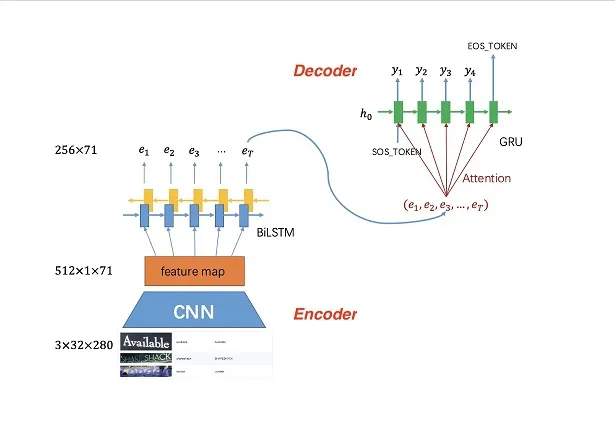
Our Intelligent Character Recognition technology combines traditional OCR with advanced Large Language Models (LLM), capable of recognizing text in images or documents within seconds while deeply understanding semantic context. The system supports JPG, PNG, PDF, TIFF, and other common formats — whether scanned documents, smartphone photos, or multi-page PDF reports — efficiently processing and outputting structured text data.
Unlike traditional OCR that merely reads characters, our system uses LLM to further understand document semantics — automatically correcting recognition errors, filling in missing text, and inferring professional terminology from context. Simply upload an image or document and the system completes recognition, semantic analysis, and output automatically, dramatically reducing manual input and proofreading time. Whether for contract review in finance, quality inspection in manufacturing, or content digitization in media, OCR + LLM delivers significant workflow efficiency gains.
For the large volumes of contracts, invoices, and reports that enterprises handle daily, the system rapidly performs batch recognition and converts them to structured digital data. Combined with LLM semantic understanding, it automatically extracts key fields (such as amounts, dates, and signatory parties) and performs preliminary compliance checks, dramatically reducing manual review time and the risk of human error.
Capture TV news tickers, program subtitles, advertising text, and magazine or newspaper image-text content in real time, automatically converting them to searchable text data. Combined with a keyword matching engine, quickly grasp brand exposure, competitor activity, and public sentiment trends — an essential tool for PR and marketing teams conducting media monitoring.
Automatically recognize numerical values and text on production line machine dashboards and measurement device displays, instantly converting them to digital data and feeding them back to MES or ERP systems. Replacing manual transcription, this not only improves data timeliness and accuracy, but also enables automated production line quality monitoring and early warning through anomaly detection.
Precisely recognize complex table structures and handwritten form content, automatically preserving row-column relationships and outputting to Excel or CSV format. Whether financial statements, shipping documents, medical records, or surveys, the system correctly parses merged cells, multi-level headers, and other complex layouts, eliminating tedious manual reconstruction.
Supports recognition of Traditional Chinese, Simplified Chinese, English, Japanese, and other languages, and can handle mixed-language documents such as Chinese-English or Chinese-Japanese combinations. The system maintains high recognition accuracy for Chinese-specific traditional/simplified variants, rare characters, and Japanese kanji-kana mixed text — ideal for multinational enterprises and multilingual document processing.
Breaking through the limitations of traditional OCR that can only read characters one by one, combining large language models to deeply understand document semantics. The system can automatically summarize lengthy documents, answer questions about document content, annotate key information, and detect contradictions or anomalies. Upgrading document recognition from 'seeing text' to 'understanding content'.
Cloud and On-Premise Deployment
Supports JPG / PNG / PDF / TIFF
Traditional Chinese / Simplified Chinese / English / Japanese
OCR + LLM Semantic Recognition