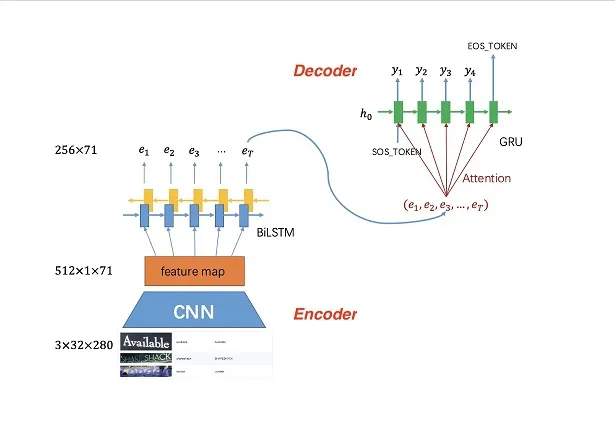
当社の「インテリジェント文字認識技術」は、従来のOCRと先進的な大規模言語モデル(LLM)を融合し、数秒で画像やドキュメントのテキストを認識するだけでなく、テキストの内容と意味的文脈を深く理解します。JPG・PNG・PDF・TIFFなどの一般的な画像・文書形式に対応し、スキャン文書・スマートフォン写真・複数ページのPDFレポートを問わず、効率的に処理して構造化テキストデータを出力します。
従来のOCRが文字を一つずつ認識するだけであるのとは異なり、当社のシステムはLLMを通じて文書の意味をさらに深く理解し、認識エラーの自動修正・欠落テキストの補完・文脈に基づく専門用語の判断が可能です。画像や文書をアップロードするだけで、システムが自動的に認識・意味解析・結果出力を完了し、手入力と校正の時間を大幅に削減します。金融業の契約審査・製造業の品質検査・メディア産業のコンテンツデジタル化など、OCR + LLMはあらゆるワークフローに顕著な効率向上をもたらします。
企業が日常的に扱う大量の契約書・請求書・帳票などの紙文書に対して、システムが迅速にバッチ認識を行い、構造化デジタルデータに変換します。LLMの意味理解と組み合わせ、金額・日付・署名者などの重要フィールドを自動抽出しコンプライアンスの初期照合も行うことで、人工審査時間を大幅に短縮しヒューマンエラーのリスクを低減します。
テレビニュースのテロップ・番組字幕・広告テキスト、および雑誌・新聞の画像テキストをリアルタイムで取得し、検索可能なテキストデータに自動変換します。キーワードマッチングエンジンと組み合わせ、ブランドの露出状況・競合動向・世論の流れを素早く把握できる、PRおよびマーケティングチームのメディアモニタリングに不可欠なツールです。
生産ラインの機器ダッシュボードや測定機器のディスプレイに表示された数値とテキストを自動認識し、リアルタイムでデジタルデータに変換してMESまたはERPシステムに返送します。手動入力プロセスを置き換え、データのリアルタイム性と正確性を向上させるとともに、異常値検出と組み合わせて生産ライン品質の自動監視と早期警告を実現します。
複雑な表の構造や手書きフォームの内容を精確に認識し、行列の関係を自動保持してExcelまたはCSV形式で出力します。財務報告書・出荷伝票・医療記録・アンケートを問わず、セルの結合や多段階ヘッダーなどの複雑なレイアウトを正確に解析し、煩雑な手動再構築作業を省きます。
繁体字中国語・簡体字中国語・英語・日本語など多言語の認識に対応し、中英混在・中日混在などの混合言語文書も処理可能です。中国語特有の繁簡体の変体・異体字、および日本語の漢字・かな混用といった状況でも高い認識精度を維持し、グローバル企業や多言語文書処理のニーズに対応します。
文字を一つずつ認識するだけという従来のOCRの限界を打ち破り、大規模言語モデルを組み合わせて文書の意味を深く理解します。システムは長文文書の自動要約・文書内容に関する質問への回答・重要情報のアノテーション・文書内の矛盾や異常の検出が可能です。文書認識を「文字が見える」から「内容が読み解ける」へとアップグレードします。
クラウドおよびオンプレミス展開
JPG / PNG / PDF / TIFFに対応
繁体字 / 簡体字 / 英語 / 日本語 多言語対応
OCR + LLM 意味認識