企業求生指南:如何在 ChatGPT 帶動的人工智慧浪潮中立足?
2026年企業AI進入全面落地階段,七成以上企業已將生成式AI納入日常營運,AI預算持續擴增,近四成企業年度增幅逾10%。AI代理人(Agentic AI)成為市場新焦點,能自主規劃目標、選擇工具並執行多步驟複雜任務,44%企業已完成部署或評估,惟技術人才短缺、資料治理框架不完善仍是主要阻礙,全面落地者僅佔6%。《歐盟AI法案》於2026年8月對高風險AI系統正式生效,涵蓋人力資源、信貸審核與教育決策等多個領域,企業須建立完整資料溯源機制、人工監督節點與風險分級標籤,逾半數企業坦言尚未充分準備。效益方面,66%企業已見生產力顯著提升,但真正以AI驅動營收增長者僅佔20%,從「技術導入」到「商業獲利」仍是2026年企業AI的核心挑戰。掌握代理人自動化、合規治理與AI工作流程優化三大方向,才能在AI全面普及的時代確立持久競爭優勢。

雖然ChatGPT 已經成為多數上班族日常工作不可或缺的得力助手,但是人工智慧畢竟不是萬能,無法知道各家企業內部的獨特流程與專業知識,為了能夠讓 ChatGPT 也能應用於企業內部,企業可以採取以下幾個方法,客製一個企業專屬的人工智慧助理:
1. 訓練企業專屬的大型語言模型
ChatGPT 從撰寫文章、回覆信件到撰寫程式碼,可說是樣樣精通,但是上班時ChatGPT 上問跟公司相關的問題是個明智之舉嗎?三星的慘痛教訓已經給了我們答案。而且不只公司機密有外洩的可能,個人的對談紀錄也有可能因為OpenAI 的保護不當而外洩。 為了避免公司重要機密外洩,同時能根據需求客製模型,公司自行訓練語言模型似乎是個明智之舉。不過首先,我們要釐清是要訓練專門回答企業問題的大型語言模型,還是像 ChatGPT 這類的通用大型語言模型。
若打算訓練跟 ChatGPT 相似的通用大型語言模型,你得確保公司有足夠的資金。據《ChatGPT 需要多少計算能力》(How much computing power does ChatGPT need) 指出,GPT-3 單次訓練成本約為 140 萬美元,而更大的語言模型訓練成本則介於 200 萬至 1,200 萬美元之間。再者,OpenAI 如何訓練 ChatGPT 的方法尚屬商業機密。除非公司的規模是像 Google、Meta 這樣的企業擁有眾多 AI 專家和充裕資金,訓練通用大型語言模型才不至於遙不可及。
但也別太早放棄,企業其實有機會能訓練專門回答企業問題的大型語言模型。今年二月,Meta (Facebook) 推出他們的大型語言模型 LLaMA,並公開研究論文,自此之後,許多學術團隊跟新創團隊便開始修改LLaMA,提出可以在資源有限的情況下可以運行的AI 模型,其中以Alpaca 最為出名。史丹佛大學的研究團隊以 LLaMA 的模型作為基底,並用OpenAI Text-Davinci-003 (GPT-3.5) 的產出微調 LLaMA 7B 模型,根據Stanford CRFM 官方說明,以不到600美元的成本就可以訓練一個小型的語言模型。
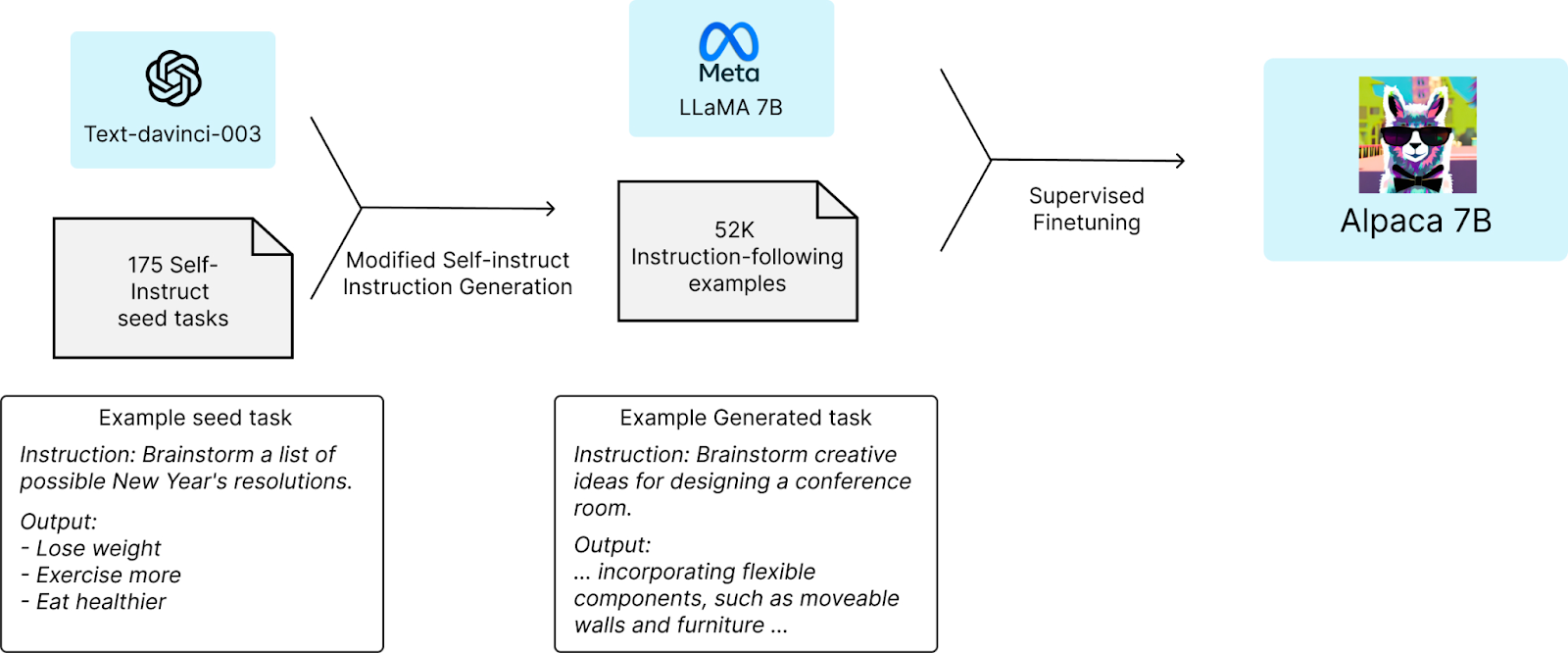
Stanford Alpaca 模型訓練過程(source: Stanford CRFM)
除了 Alpaca 外,4月初,UC Berkeley, CMU, Stanford 和 UC San Diego的聯合團隊利用從ShareGPT 上取得的使用者對話微調 LLaMA 13B 的模型,訓練出Vicuna-13B,宣稱該模型能力媲美ChatGPT 90% 的水準,該團隊隨後也將該模型權重公開放在Github 的 FastChat 中。

Vicuna-13B 模型訓練過程(Source: techbriefly)
另外,還有OpenChatKit、gpt4all 以及 chatgpt_academic 等小型語言專案如雨後春筍般冒出來,雖然這些小型專案與ChatGPT、GPT-4 還有些差距,但仍值得一試。不過企業也得惦惦自己的斤兩,若缺乏充足的資料、計算能力和人才,訓練出來的模型表現可能仍不盡如人意。
但使用大型語言模型也不是全然都得靠自己,微軟Azure就有與OpenAI 合作推出相對安全、可靠的解決方案 - Azure OpenAI 服務,如果企業能更進一步遮罩(Masking)掉敏感資料,則上雲的風險相對可控。如果選擇上雲的話,企業可以考慮使用詞嵌入(Embedding)或微調(Fine-Tuning)這兩種方法來提升ChatGPT的問答能力。
2. 運用詞嵌入(Embedding)檢索企業資料
詞嵌入(Embedding) 就是把詞語映射到一個向量空間,如果詞語相關程度高則距離較近,詞語相關程度低則距離遠,聽起來可能有點抽象,因此我們先用一個簡單的例子來說明它的意思。假設你去油漆店挑選顏色,會看到各種不同的油漆顏色,例如白色就可以分為珍珠白、米白、百合白等等。不過如果要判斷米白和百合白哪個顏色比較接近珍珠白,如果沒有一個相似度比較標準,則可能會引起不少爭議。
那到底該如何比較顏色的相似度呢? 其實,對於每個顏色,我們都可以用RGB(紅、綠、藍)三個維度來表示,每個維度的數值範圍為0~255。例如紅色的RGB值為(255, 0, 0),深紅色的RGB值為(200, 0, 0),綠色的RGB值為(0, 255, 0)。透過計算維度之間的距離,就可以判斷紅色和深紅色的相似度就比紅色和綠色要高。
把同樣案例套用到文字上,來解釋文字的應用,假如我們把每個詞語看成一種顏色,例如:
-
「蘋果」代表紅色,RGB值是(255, 0, 0)
-
「草莓」代表深紅色,RGB值是(200, 0, 0)
-
「青蛙」代表綠色,RGB值是(0, 255, 0)

詞嵌入-把詞語映射到向量空間
在「詞嵌入」的概念裡,我們可以透過比較這些顏色的相似程度,來判斷詞語間的關係。比如說,蘋果和草莓都屬於紅色系列,它們的RGB值差異較小,顯示這兩個詞語有相似的意義。然而,青蛙是綠色的,與蘋果和草莓的顏色有很大的差距,因此青蛙跟蘋果、草莓在意義上的距離比較遠。透過「詞嵌入」電腦就能更好地理解詞語之間的語義關係,從而提高自然語言處理的能力。
OpenAI的API提供了一個詞嵌入模型(text-embedding-ada-002),它可以把公司知識庫的每條知識壓縮成詞嵌入(或向量),並存儲在資料庫(例如:ElasticSearch、Milvus 、Pinecone 或 PostgreSQL 的擴充套件 pgvector)中。之後當企業用戶提出問題時,我們就可以在資料庫中搜索(K Nearest Neighbor)到與問題最相近的知識,然後將問題連同公司內部知識一起作為ChatGPT的輸入。這樣一來,ChatGPT就可以根據事實給出合適的回答,而不會一本正經的胡說八道。
3. 運用微調(Fine-tuning)客製專屬模型
如果嫌 ChatGPT 的回答不夠客製化,我們還可以透過微調 (Fine-Tuning) 技巧客製企業專屬模型。除了使用 OpenAI 已經提供好的大型基底模型外,OpenAI 允許開發者利用自己的數據集對模型進行微調,以適應特定的任務。例如,假設您想要為公司打造一個專門專門回覆電子郵件的模型。首先,您需要收集大量與您業務領域相關的數據,如客戶郵件內容與官方回應。接著,便可利用這些數據對 GPT-3.5 進行微調(目前只開放 Davinci 系列可以微調,GPT-4 跟 ChatGPT 尚無法微調 ),讓GPT-3.5 學會公司特有的語言風格和慣用語。經過微調後,就可以獲得一個高度客製化的電子郵件回覆模型。

微調(Fine-Tuning) 模型 (source: Feature-based Transfer Learning vs Fine Tuning?)
微調主要包括以下幾個步驟:
-
1. 準備微調數據集:挑選與任務相關的數據集,數據集應包含足夠多的樣本(越多越好,但至少要500筆以上),讓模型能夠學到任務所需的知識和風格
-
2. 微調:在選定的數據集上對 GPT-3.5 進行二次訓練。在此過程中,模型會根據新數據集進一步學習,並對特定任務進行優化。例如,若數據集包含大量客服對話,經過微調後的模型將更擅長處理客服相關問題
-
3. 評估與調整:對微調後的 GPT-3.5 進行評估,確保其表現符合預期。若模型表現不佳,可通過調整數據集或進行多次微調來優化模型
透過以上微調機制,利用企業特定數據進行對GPT-3.5 再訓練,讓模型更好地理解公司內部的業務流程和專業術語。這個過程相對節省時間和計算資源,因為原有的基底模型(GPT-3.5)已經具備基本的語言理解能力,經過微調,模型便能更好地適應企業內部的特定業務需求,這不僅有助於提升企業的業務效率,還能夠為客戶提供更優質的服務。
然而,微調也不是盡善盡美。在訓練過程中,模型可能會過度學習(擬合)企業特定的知識,導致微調後的模型只能回答與企業相關的問題,而喪失 GPT-3.5 原本強大的對話能力(泛化能力降低)。此外,如果企業提供的對話數據量過少,微調的效果可能受限。因此,企業內部需要擁有資料科學家等專才,才能對模型進行調整與優化,讓微調 後的模型符合企業預期。
2026年企業AI新趨勢:從試驗走向全面落地
距離ChatGPT問世已逾三年,2026年的企業AI版圖早已天翻地覆。生成式AI不再只是試點項目,而是深入企業日常運營的核心基礎設施。根據Deloitte《2026企業AI現狀報告》,超過七成企業已將生成式AI納入營運流程,AI預算持續攀升——86%的受訪企業表示2026年AI預算將增加,其中近四成增幅超過10%。
AI代理人(Agentic AI)成為新主角
2025年企業界大規模實驗AI代理人,2026年初已有44%的企業完成部署或評估。AI代理人能自主推理、選擇工具、執行多步驟任務,遠超過傳統問答式AI助理的能力邊界。然而全面落地的企業仍僅佔6%,治理框架與人才缺口是最大瓶頸——46%的技術主管坦承AI技能不足是最大障礙。
歐盟AI法案2026年正式生效,合規成企業必修課
2026年8月,《歐盟AI法案》(EU AI Act)針對高風險AI系統的義務正式生效,涵蓋人力資源、信貸審核、教育等領域。企業須建立完整的資料溯源、人工監督節點,以及AI系統風險分級標籤。逾半數企業尚未建立AI系統清冊,合規缺口顯著,亞太企業也面臨與歐盟客戶往來時的間接適用壓力。
效益與挑戰並行:ROI落地仍待突破
目前企業AI最顯著的成效集中於生產力提升——66%的企業已見效。然而在營收增長方面,74%的企業仍停留在「期望」階段,真正實現者僅20%。2026年企業AI投資的首要優先項目是優化AI工作流程與生產週期(佔42%),其次是拓展新應用場景(31%)。從「導入AI」到「用AI獲利」,企業仍需跨越從技術到商業的關鍵一躍。
結論
ChatGPT 的問世,讓我們深感人工智慧的奇點已經逼近!除了每個人都應該將 ChatGPT 融入日常生活和工作中外,企業更應早日領悟人工智慧所帶來的巨大變革,將其應用融入企業運營流程,甚至創造全新的人工智慧產品,以避免被人工智慧時代的變革淘汰。
企業應用 ChatGPT 的解決方案包含自行訓練一個大型語言模型,這需要龐大的資金、計算能力和專業人才,對大多數中小型企業來說並不適合。 然而,中小企業同樣可以通過詞嵌入或微調的方式,利用公司內部知識庫來拓展 ChatGPT 的能力,提升其問答水準,避免因人工智慧無法理解企業專業術語或內部流程而引發的問題。當然,無論是自建、詞嵌入或微調,企業仍需投入適量的人力資源(例如:資料科學家),才能不斷調整和優化模型,確保模型達到預期效果。
還在等待人工智慧取代你的公司或崗位嗎?現在就是採取行動的時刻!作為企業,時代的巨輪已經讓你無法繼續墨守成規,踏出創新的一步,將人工智慧助手納入企業運營中,開創新的業務領域,才有辦法創造未來!
延伸閱讀:看看大數軟體是怎麼運用ChatGPT到公司產品與企業流程中的,ChatGPT:文字探勘領域的顛覆者,自動化輿情分析的利器