開源 AI 模型比較 2026:Llama、DeepSeek、Taide 企業選型全攻略
開源大型語言模型(LLM)持續演進,2026年企業採用率已超過80%。Meta的Llama 4採原生多模態架構,Maverick版支援100萬token上下文;DeepSeek V3.2引入稀疏注意力機制,代理推理能力比肩GPT-5,以MIT授權開源;阿里雲Qwen3.5支援201種語言,具備思考與對話模式切換;Mistral Large 3以Apache 2.0授權釋出。37%的企業已採混合AI策略,同時部署開源與閉源模型。企業可透過Hugging Face取得模型,以Ollama或LM Studio地端部署,並以MMLU、Chatbot Arena等基準評估中文能力與性價比,在資料安全與成本間取得最佳平衡。
Llama 引領開源大型語言模型風潮
OpenAI 於 2022 年推出 ChatGPT 後,人工智慧的發展掀起了一股熱潮。除了大型科技公司競相開發自己的 ChatGPT 替代品外,開源社區也開始透過群眾力量開發開源的大型語言模型(Large Language Models, LLMs),希望能夠讓世界各地的人都能免費使用這些強大的語言模型。
閉源模型通常由大型科技公司開發,如 OpenAI 的 ChatGPT 系列、Google 的 Gemini、法國新創公司的 Mistral 以及 Anthropic 的 Claude 等。這些模型通常以 API 的方式開放,允許使用者從雲端存取並按需計費。這樣一來,使用者無需自行架設或購買硬體,就能利用 API 開發出屬於自己的人工智慧應用。
然而,儘管閉源語言模型的使用十分便捷,但也存在一些隱憂。首先,如果使用量大,價格可能會相當昂貴;其次,公司內部可能有機密或個人資料,若透過雲端存取 API,可能會導致這些敏感資料外洩。因此,對於希望將資料保存在公司內部的企業而言,開源模型成為了首選。
然而,開發一個大型語言模型需要投入大量資金,單靠開源社區的貢獻是無法建立高性能的模型。直到 Meta 開發的 Llama 改變了這一切。
Meta Llama
LLaMA 是 Meta AI 從 2023 年 2 月開始發布的一系列自回歸大型語言模型。第一版 LLaMA 訓練了四種模型尺寸:7B、13B、33B 和 65B 參數。有了 Meta 的 LLaMA 作為基礎,所有的新創公司和開源組織都紛紛以 LLaMA 為基礎(例如台灣的 Taide)開發出屬於自己的大型語言模型。儘管如此,這些模型的效能仍然遜於閉源模型,直到 Llama 3 的推出再次改變了局勢。
Llama 3 於各大雲端平台重磅登場
2024 年 4 月 18 日,馬克·祖克柏(Mark Zuckerberg)在 Facebook 平台上重磅發布了 Llama 3,這是 Meta 最新一代的開源大型語言模型。Llama 3 模型隨即在 Hugging Chat、Microsoft Azure 等平台上線。此次推出的 Llama 3 具有以下關鍵特點:
- 頂尖性能:Llama 3 的 8B 和 70B 參數模型在各自規模上都取得了最佳的開源模型性能。與 Llama 2 相比,在推理、程式碼生成和指令遵循等方面,Llama 3 展現出顯著提升的能力,使其更易於控制。
- 創新模型架構:Llama 3 使用了一個包含 128K tokens 的 tokenizer,可以更有效地編碼語言,大幅提高模型性能。為了提升推理效率,Llama 3 在 8B 和 70B 的尺寸上都採用了分組查詢注意力(Grouped Query Attention, GQA)機制。
- 高質量訓練數據:Llama 3 在超過 15 兆 tokens 上進行了預訓練,訓練數據集比 Llama 2 使用的數據集大 7 倍,其中包含的程式碼量是 Llama 2 的 4 倍。為了支援多語言能力,Llama 3 的預訓練數據集中有超過 5% 是高質量的非英語數據,涵蓋了 30 多種語言。Meta 還開發了一系列數據清理流程,以確保 Llama 3 訓練使用的是最高品質的數據。
- 擴大預訓練規模:為了有效利用預訓練數據,Meta 在擴大 Llama 3 模型的預訓練規模方面做了大量工作。他們開發了一系列詳細的縮放定律(Scaling Laws),用於下游基準測試評估,這有助於在實際訓練最大模型之前,預測其在關鍵任務上的性能。為了訓練最大的 Llama 3 模型,Meta 結合了數據、模型和資料處理流程(pipeline)的平行化。
- 指令微調:為了在聊天應用中充分發揮預訓練模型的潛力,Meta 還創新了指令微調方法。他們的後訓練(Post Training)方法結合了監督微調(Supervised Fine Tuning)、拒絕採樣(rejection sampling)、近端策略優化(proximal policy optimization, PPO)和直接策略優化(direct policy optimization, DPO)。
Llama 3 的 8B 模型已經是同級尺寸模型(7B)系列中的最佳模型,而 Llama 3 的 70B 模型與 Claude 3 Sonnet 的效果同樣出色,但價格卻便宜了 10 倍!目前正在訓練的 Llama 3 400B 模型,測試結果已經與 GPT-4 Turbo 和 Claude 3 Opus 不相上下,完全超越了 Gemini Pro 1.5。Llama 3 的問世無疑對這些閉源模型開發公司和 AI 巨頭構成了巨大威脅。
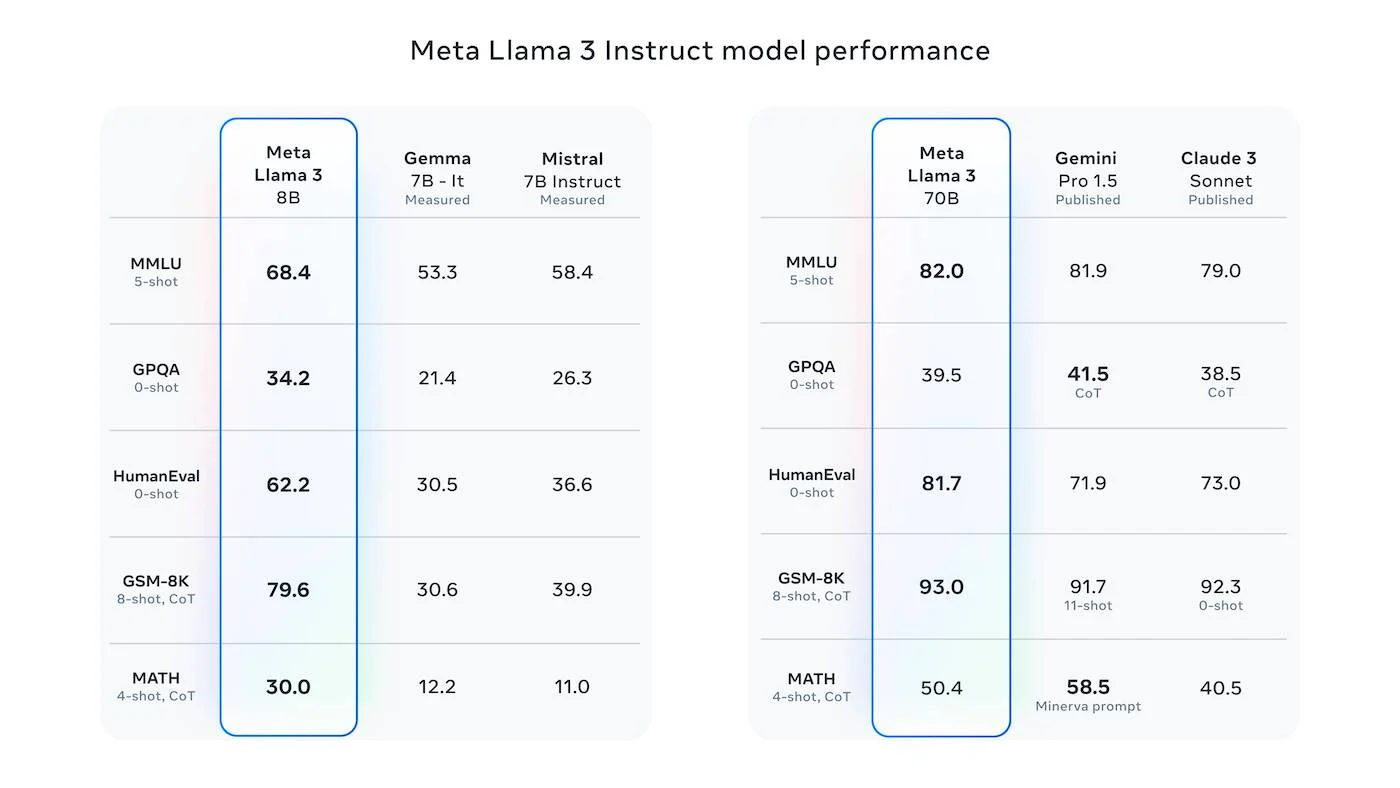
Llama3 模型性能
DeepSeek R1:人工智慧領域的新興競爭者

在開源人工智慧領域,除了Meta的Llama系列,中國的DeepSeek R1也是一個值得關注的新興力量。DeepSeek(深度求索)於2023年7月由梁文鋒創辦,總部位於中國杭州。梁文鋒同時也是中國對沖基金「幻方量化(High-Flyer)」的共同創辦人,DeepSeek因此獲得了該基金的支持。
DeepSeek R1的技術與創新特色
DeepSeek R1於2025年1月20日正式發表,是一款專注於推理能力的大型語言模型。與其他模型相較,R1具有以下技術特點:
- 混合專家架構:擁有671B參數,但採用混合專家(Mixture-of-Experts)架構,每次推理僅啟用約37B參數,大幅提高運算效率。
- 超長上下文窗口:上下文長度達128K token,遠超多數同類模型。
- 強化學習訓練:DeepSeek採取獨特的強化式學習路線,最初版本R1-Zero直接對預先訓練模型進行大規模強化學習,沒有經過常規的監督式微調。
- 知識蒸餾:團隊將R1的大模型知識提取並壓縮到更小的模型上,使參數量較小的模型也能獲得接近R1的推理能力。
R1的競爭優勢
DeepSeek R1在市場上最大的優勢是開源和成本效益:
- 開源免費:R1在MIT許可下開源發布,允許免費商業與研究使用。
- 低成本:據報導,R1的訓練成本不到600萬美元,遠低於OpenAI訓練GPT-4所需的數億美元。
- API價格優勢:R1的API每百萬個token的輸入僅約$0.55(OpenAI同級模型約$15),輸出每百萬token約$2.19(OpenAI約$60)。
在效能方面,R1的表現可與當前最先進的西方大型模型相媲美,在Chatbot Arena評測中名列前茅,超越了多個知名模型。
然而,R1在安全和法規遵循方面仍面臨挑戰,研究顯示R1相較於其他模型更容易被越獄(jailbreak),這意味著DeepSeek在模型對齊與風險控制上仍有改進空間。
市場影響
DeepSeek R1的成功已對人工智慧市場產生深遠影響:
- 2025年初,搭載R1的DeepSeek Chat迅速攀升至蘋果App Store免費榜第一名,一度超越ChatGPT。
- R1的低成本高效能引發業界對傳統人工智慧商業模式的重新思考。
- 因R1展示了降低對昂貴硬體依賴的可能性,NVIDIA等人工智慧晶片製造商股價曾大幅波動。
未來,DeepSeek可能會開發R2或進階版本模型,重點強化模型的對齊和安全性,並朝多模態融合方向發展。在市場策略上,可能採取「開源+商業服務」的雙軌路徑,一方面開源核心模型,另一方面提供加值服務。
開源模型與他們的產地 - Hugging Face 平台介紹
那麼,我們該如何使用開源模型呢?讓我們先來介紹開源模型的發源地:Hugging Face。

Hugging Face
Hugging Face 是一個在人工智慧領域享有盛譽的開源平台,為開發者和研究者提供了豐富的預訓練模型、高質量的數據集以及強大的實用工具。該平台致力於推動人工智慧技術的民主化進程,讓更多人能夠接觸到並應用最先進的 AI 模型。
Hugging Face 提供了一個直觀且易於使用的搜索界面,使用者可以根據自己的需求,快速找到最適合的模型。以當前備受矚目的大語言模型 LLaMA3 為例,使用者只需在搜索框中輸入關鍵字(如「llama3」),即可查找到相關模型。值得注意的是,搜索結果中可能同時包含官方發布的模型和社區成員貢獻的微調版本。因此,在選擇模型時,建議仔細查看模型名稱前的提供者資訊,以確保下載到正確且可靠的版本。
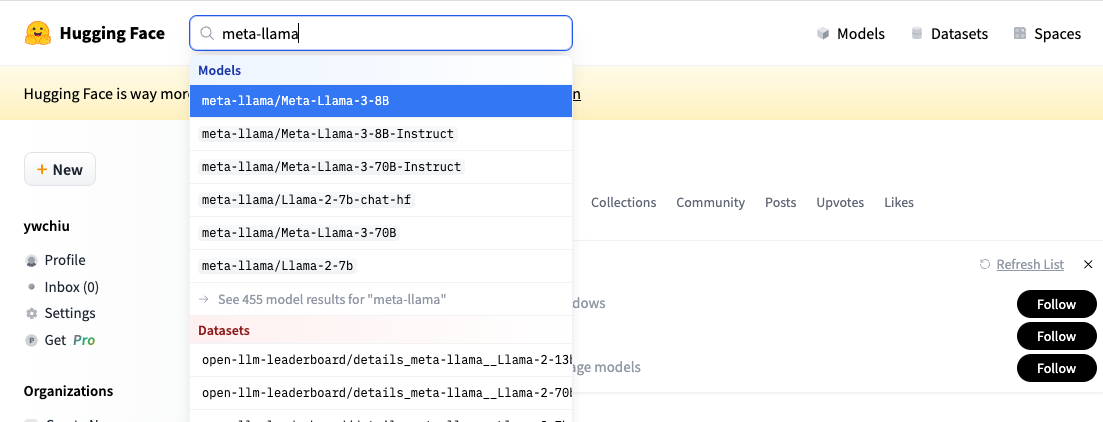
在Hugging Face 搜尋模型
除了豐富的模型資源,Hugging Face 還提供了數據集(datasets)和模型示範空間(spaces)等實用功能,幫助使用者更好地理解和應用這些開源模型,提升人工智慧項目的開發效率。
解析大型語言模型命名規則,選擇合適的模型
Hugging Face 上的模型名稱通常蘊含了豐富的信息,深入理解這些命名規則,有助於使用者選擇最適合自己需求的模型。以下是幾個模型家族的命名範例:
1. llama-3-8B-Instruct:
- `8B` 表示模型的參數量為 80 億(8 Billion),參數量越大,模型的表現通常越好,但計算資源需求也越高。
- `Instruct` 表示模型使用了指令微調(Instruction Tuning)方法進行訓練,使其能夠更好地適應特定任務。
2. llama-3-8B-Instruct-GGUF:
- `8B` 表示參數量為 80 億(8 Billion)。
- `Instruct` 表示使用了指令微調。
- `GGUF` 表示模型文件採用了 GPT-Generated Unified Format 格式,具有良好的可擴展性、兼容性和易用性。
3. llama-2-7b-chat-hf:
- `7B` 表示參數量為 70 億(7 Billion)。
- `chat` 表示模型專門為對話任務進行了優化,在聊天機器人等應用中表現出色。
- `hf` 表示模型文件使用了 Hugging Face 的格式,便於在該平台上進行部署和應用。
4. Qwen1.5-32B-Chat-GPTQ-Int4:
- `32B` 表示參數量為 320 億(32 Billion),是一個超大規模的模型。
- `chat` 表示模型專門為對話任務進行了優化。
- `GPTQ` 表示使用了 GPTQ(GPT Quantization)方法,這是一種針對 GPU 優化的量化技術,可以在保持模型性能的同時,減少計算資源需求。
- `Int4` 表示使用 4 位整數對模型進行量化,這種量化方式可以大幅壓縮模型,但模型精準度也會跟著下降。
Hugging Face 為開發者和研究者提供了一個便捷的平台,讓他們能夠快速找到優質的開源大語言模型,大大簡化了開發 AI 應用的過程。
在本地端安裝與執行大型開源模型的最佳解決方案:LM Studio vs. Ollama
隨著大型語言模型(LLM)的迅速發展,越來越多的開發者和研究人員希望在本地環境中運行這些開源模型。然而,對於許多使用者來說,在本地端配置環境並透過Python 撰寫程式運行從 Hugging Face 等平台下載的開源模型可能是一個挑戰。
為了解決這個問題,一些開發者提供了易用的工具,如 LM Studio 和 Ollama,使得在本地環境中使用大型開源模型變得更加方便。
LM Studio:功能豐富的本地 LLM 工具
LM Studio 是一款功能豐富的桌面應用程序,旨在幫助使用者在本地端上運行大型語言模型。
LM Studio
LM Studio具有以下特點:
- 隱私保護:通過在本地運行 LLM,避免了數據外洩的風險,提供了更好的隱私保護。
- GPU 加速:支持 GPU 加速模型的運行,提高模型推理速度。
- 跨平台支持:提供了 Windows、macOS 和 Linux 等多個平台的版本。
- 豐富的模型選擇:LM Studio 提供了來自 Hugging Face 等平台的大量預訓練模型,使用者可以根據需要選擇合適的模型。
使用 LM Studio 非常簡單,只需下載對應平台的安裝程式,選擇要下載的模型,等待模型下載完成後即可開始使用。
在 LM Studio 中使用 Llama 3
接下來,讓我們一步步介紹如何在 LM Studio 中使用 Llama 3。
1. 下載並安裝 LM Studio:首先,您需要從 LM Studio 的官網下載並安裝最新版本的 LM Studio。
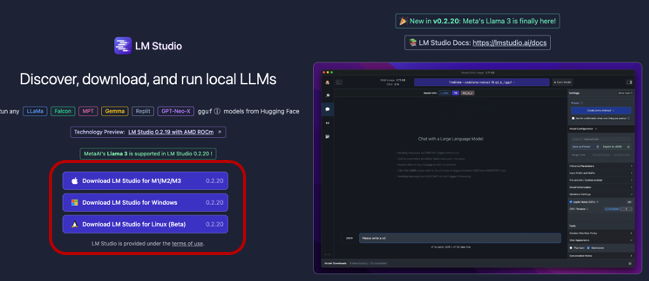
下載安裝檔案
2. 搜索並下載 Llama 3 模型:打開 LM Studio 後,在應用內的搜索頁面中搜索 "lmstudio-community/llama-3",然後從搜索結果中選擇一個下載選項。LM Studio 會自動下載並安裝所選的 Llama 3 模型。
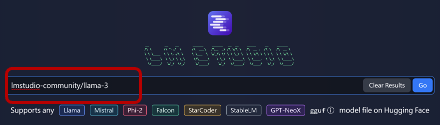
搜尋lmstudio-community/llama-3
3. 選擇合適的模型版本:Llama 3 提供基礎版(Base)和指令微調版(Instruct),以及分為8B 與 70B 兩種尺寸,在硬體資源不豐富的情況下,選 lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF 即可。

選擇 lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF
4. 開始使用 Llama 3:選擇合適的模型變體後,您就可以開始使用 Llama 3 了。您可以通過 LM Studio 提供的聊天界面與模型互動,或者通過本地 LLM API 服務器調用模型。
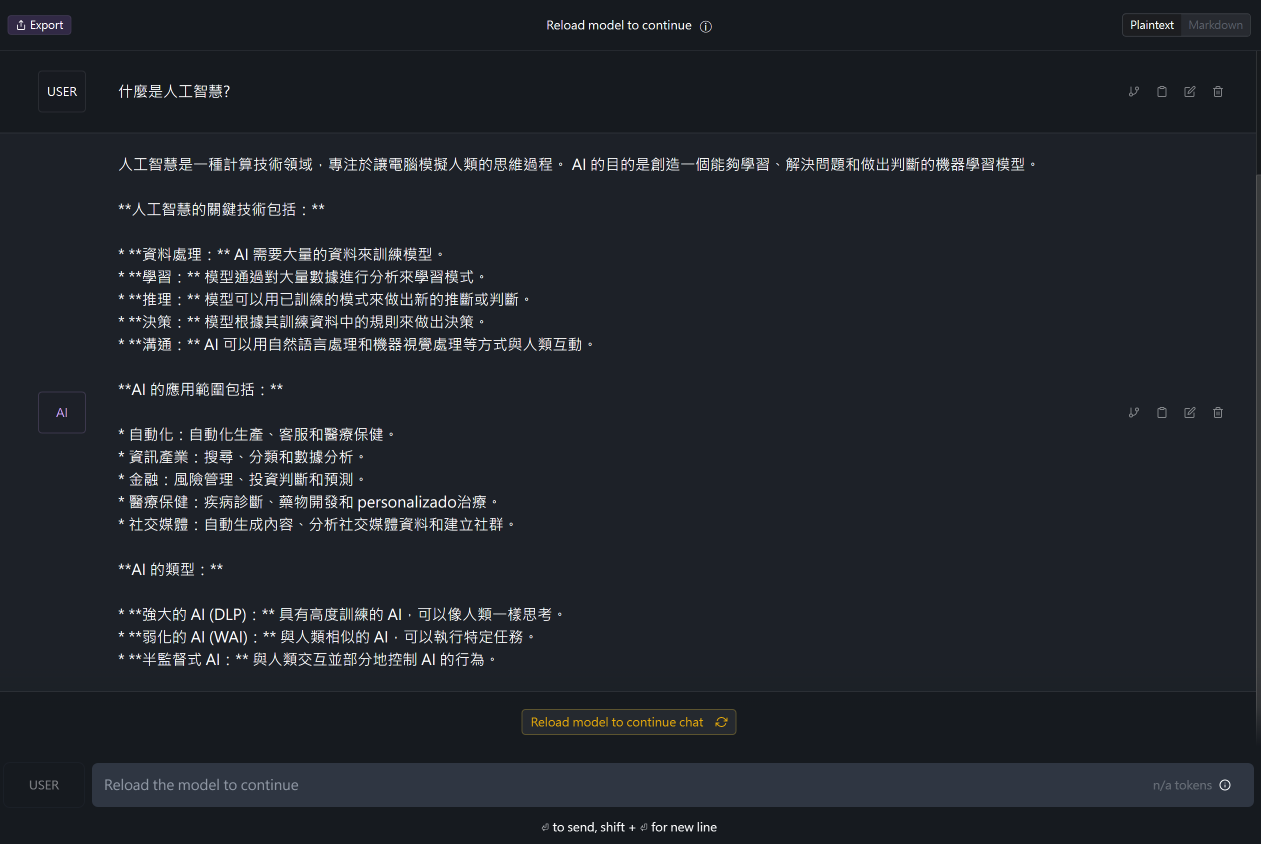
LM Studio 對話介面
如何在 LM Studio 中使用 DeepSeek R1 蒸餾版模型 ?
Ollama:簡單易用的開源 LLM 操作平台

Ollama
Ollama 是一個開源的大型語言模型平台,允許使用者在本地端運行各種模型,如 Llama 3 等。它的設計目標是優化模型的設置和配置過程,包括 GPU 的使用。
Ollama 具有以下特點:
- 簡單易用:安裝和使用過程非常簡單,特別適合初學者和非技術使用者。
- 靈活性:支持創建自定義語言模型,並運行多個預訓練模型。
- 開源透明:完全開源,促進了社區的參與和貢獻,提高了平台的可信度。
- 多平台支持:支持 macOS、Linux 和 Windows 等主流操作系統。
- 多模態支持:支持多模態 LLM,如 llava,擴展了應用場景。
使用 Ollama 也非常簡單,只需在支持的平台上下載並安裝,然後下載感興趣的模型,指定模型的具體版本,使用 `ollama run` 命令即可直接通過命令行或 API 與模型對話。
在 Ollama 中使用 Llama 3
1. 下載並安裝 Ollama:首先,您需要下載並安裝 Ollama。Ollama 支持 Windows、macOS 和 Linux 平台。
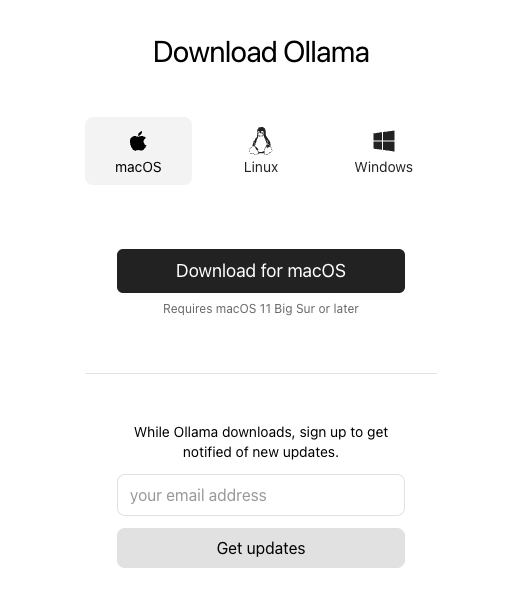
下載 Ollama
2. 尋找 llama3 模型: 在ollama 官網的右上角可以輸入 llama3,搜尋llama3 的模型卡片與啟動指令
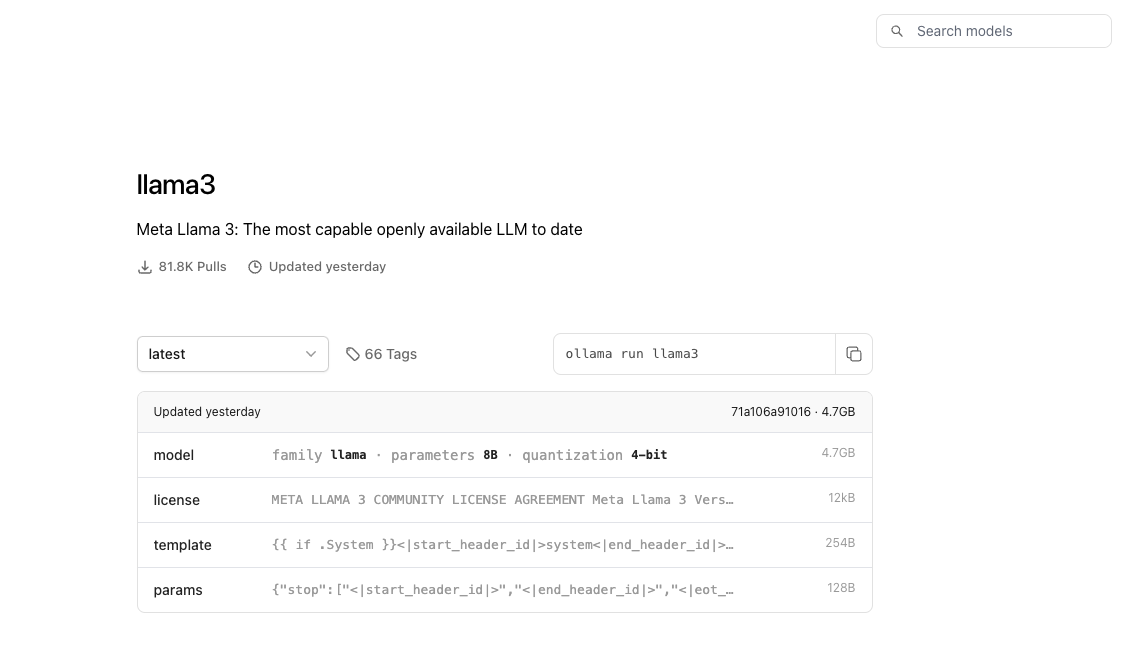
Llama3 模型卡片
3. 運行 Llama 3:安裝完 Ollama 後,您可以在終端機 (Terminal) 或 Windows Power Shell使用以下命令運行 Llama 3:
ollama run llama3
這個命令將下載並運行 Llama 3 的預設版本(8B 參數)。
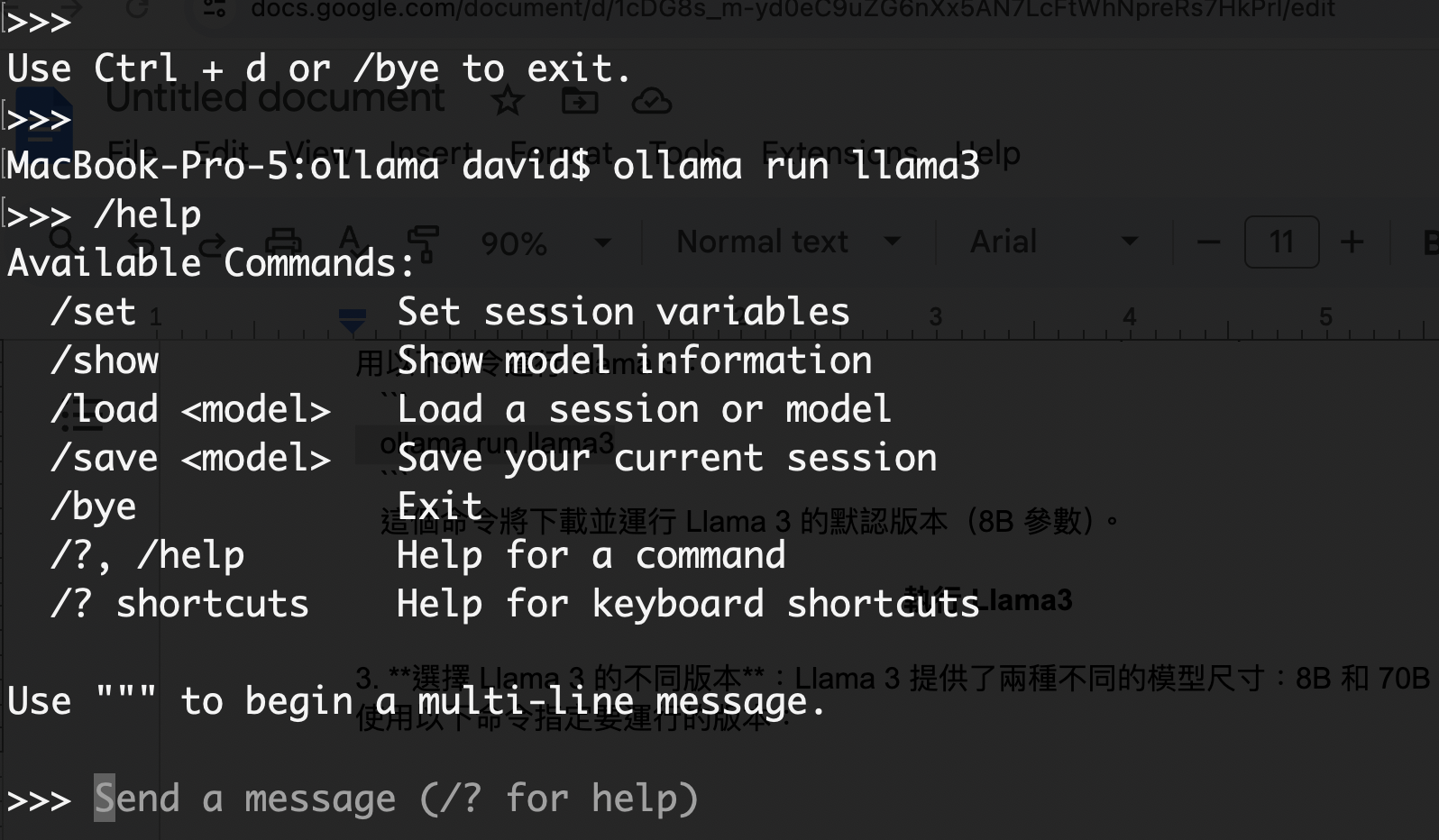
執行 Llama3
4. 設定系統提示詞:如果使用 Llama 3 預設的提示詞,Llama3 會產出英文的回覆,因此我們可以使用 set 指令修改提示詞:
- 顯示提示詞:
/show system
- 修改提示詞:
/set system 你是一個大型語言模型,請用台灣正體中文跟我問答,所有的答覆都要用正體中文進行
- 提問:設定完提示詞以後就可以正常提問,此時所有的回覆都會是我們常見的繁體(正體)中文。
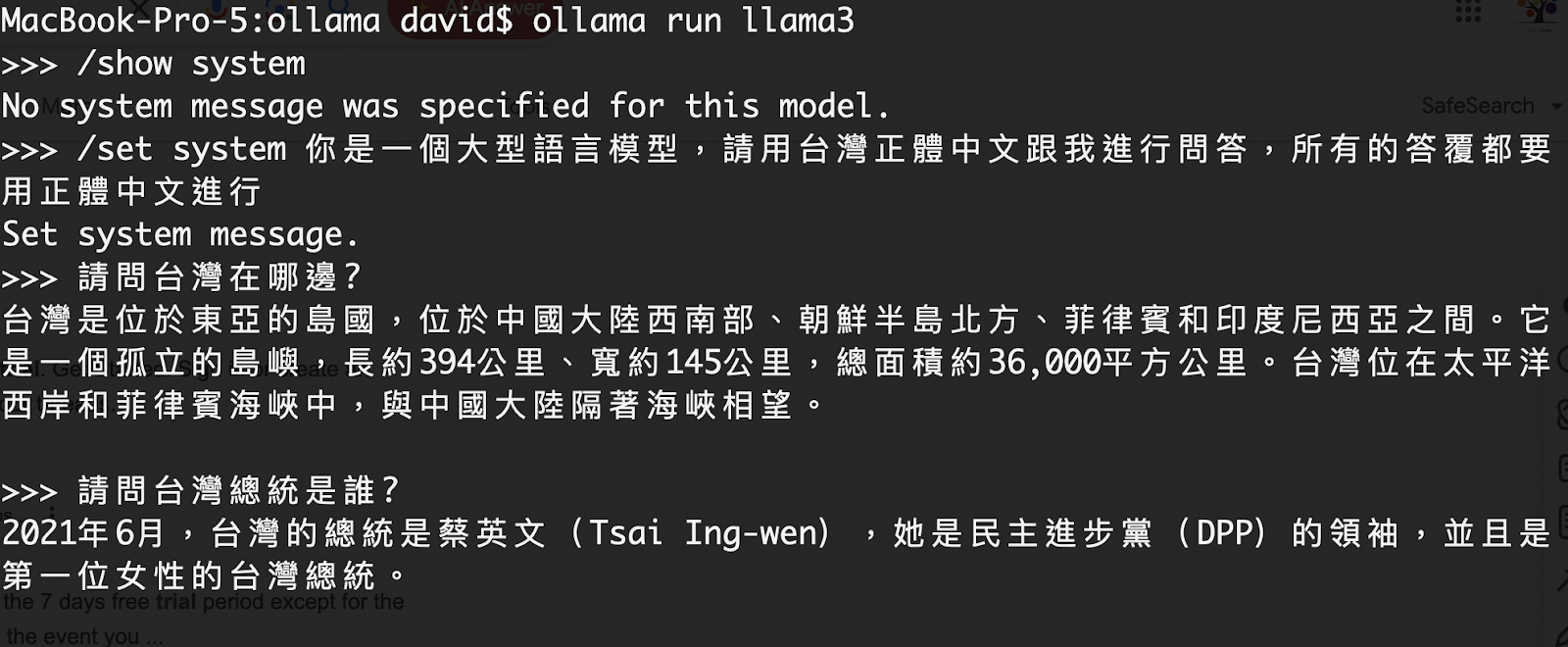
修改系統提示詞,讓Llama3 回答中文
如何在 Ollama 中使用 DeepSeek R1 蒸餾版模型?
LM Studio vs. Ollama
LM Studio 和 Ollama 都是在本地端運行大型開源模型的優秀工具,但它們在某些方面存在差異。
Ollama 以其簡單性和易於安裝而聞名,特別適合初學者和非技術使用者。相比之下,LM Studio 在使用者界面方面被認為更加友好,提供了更多來自 Hugging Face 等平台的模型選擇。
在性能方面,有報告指出 Ollama 在某些情況下比 LM Studio 更快,然而,一些使用者報告稱 Ollama 的輸出品質低於 LM Studio。
無論選擇哪種工具,LM Studio 和 Ollama 都是在本地環境中使用大型開源模型的利器。它們為使用者提供了便捷的方式,讓更多人能夠體驗和應用大型語言模型,推動了人工智能技術的普及和發展。
vLLM:提升LLM推理效能的關鍵工具
在部署和使用開源大型語言模型時,效能一直是一個關鍵挑戰。vLLM正是為解決這一問題而生的專業神器,它能顯著提升模型推理速度並優化資源利用。
什麼是vLLM?
vLLM是一個專為大型語言模型推理與服務而設計的高效庫,其名稱代表"Virtual Large Language Model"(虛擬大型語言模型)。它最初由加州伯克利大學的Sky Computing Lab開發,目標是解決在部署LLM過程中遇到的效率瓶頸。
vLLM的核心創新在於引入了PagedAttention演算法,類似作業系統的分頁概念,允許注意力機制的關鍵資料存儲在不連續的記憶體中,達到近乎零碎片和零浪費的記憶體使用。在傳統模型推理中,大量的Key-Value注意力緩存會佔用大量記憶體,且難以高效重複利用,導致資源浪費和速度下降。
實際測試表明,與Hugging Face Transformers標準實現相比,vLLM在LLM服務上的吞吐量最高可提升24倍。這意味著在相同的模型和硬體上,使用vLLM可以更快地處理使用者請求並生成回應,這對需要平行處理、多使用者的應用場景尤為重要。
vLLM的主要優勢
- 易於使用的介面:vLLM提供了簡潔的Python API和命令列工具,方便整合到現有工作流程。您可以像使用Hugging Face Transformers一樣加載模型,但享受更好的性能。初次使用時,vLLM會自動從Hugging Face下載所需的模型權重。
- OpenAI相容的本地服務:vLLM可以輕鬆啟動一個本地的模型推理服務,其API介面與OpenAI的Chat Completion/Completion介面相容。這意味著您可以使用現有的OpenAI API Client來調用本地的vLLM服務,無需另外撰寫程式碼。
- 高吞吐量與平行處理:vLLM在大量請求下表現突出。PagedAttention機制允許它巧妙地批量處理多個輸入,在不浪費計算的前提下共用大部分的計算圖和Cache。因此,如果您計劃部署一個同時為多名使用者提供服務的系統,vLLM能確保在相同硬體下處理更多請求而不降低回應速度。
- 高效的長上下文支持:vLLM的記憶體管理機制允許更有效地存儲和訪問超長的KV緩存,能更好地支持長上下文而不顯著拖慢速度。這對於需要處理長文摘要或多輪長對話的應用非常實用。
需要注意的是,vLLM的性能優勢通常需要硬體(尤其是GPU)的配合才能充分發揮。它對CUDA GPU進行了優化,也支援其他硬體加速(如AMD GPU、部分深度學習加速卡等)。在純CPU環境下,vLLM依然可運行,但由於缺乏GPU並行計算的優勢,其吞吐改善有限。
如何使用 vLLM 運行 DeepSeek R1 ?
除了Llama以外,流行的開源語言模型
隨著人工智能技術的快速發展,除了Meta的Llama系列模型外,市場上已經湧現出多種優秀的開源大型語言模型。這些模型為人工智能領域注入了新的活力,為研究人員和開發者提供了更多選擇。以下是幾個值得關注的模型:
1. Mistral-nemo:由法國團隊開發的大型語言模型Mistral在各種基準測試中表現優秀,尤其在數學、程式碼生成和推理等領域表現出色。使用者可以通過執行指令"ollama run mistral-nemo"來體驗12B版本的模型。如果擁有足夠的GPU資源,還可以載入mistral-small或mistral-large,以充分發揮其強大性能。

Ollama 的 Mistral-Nemo 模型卡
2. Taide:Taide (可信任生成式AI發展先期計畫)是一個由台灣團隊自主研發的繁體中文大型語言模型。目前,Taidey在Ollama 有放上數個版本,不過更新時間都八個月以前,請注意使用。使用者只需安裝ollama,並輸入指令"ollama run willh/taide-lx-7b-chat-4bit",即可開始體驗Taide的強大功能。
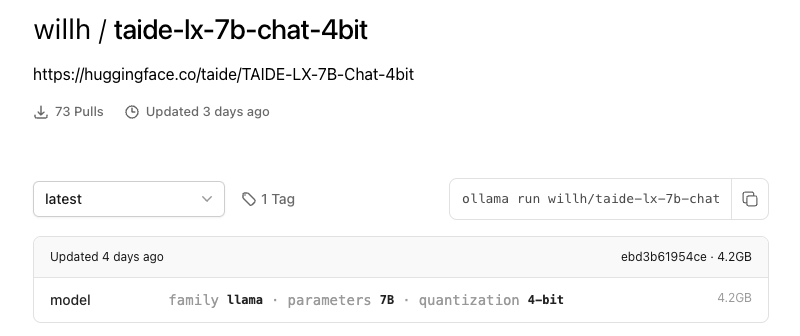
Ollama 的 Taide 模型卡
3. Breeze2:Llama-Breeze2-8B-Instruct是由聯發科技公司使用LLaMA 3.2 模型進行微調(Fine-Tune)得到的繁體中文開源模型,參數量為8B。使用者可以通過Hugging Face MediaTek-Research/Llama-Breeze2-8B-Instruct 來下載Breeze2模型。

Hugging Face 的 Breeze2 模型卡
4. QWEN2.5:QWEN(通義千問)是由阿里巴巴開發的中文問答模型,旨在提供高品質的問答服務。QWEN目前提供了多個不同參數規模的開源版本,包括0.5B、1.5B、3B、7B、14B、32B和72B。如果使用者想要執行7B的模型,可以使用指令"ollama run qwen2.5"。
此外,通義千問還有跟DeepSeek R1、ChatGPT O1、O3 類似的推理模型 QwQ-32B

Ollama 的 Qwen 2.5 模型卡
5. Gemma3:Gemma3 是由 Google DeepMind 基於與創建 Gemini 模型相同的研究和技術,開發的輕量級、先進的開源模型。2025年 3月 12 日 Google 發布了四種尺寸的模型權重:Gemma3 1B、Gemma3 4B、Gemma3 12B 和Gemma3 27B。使用者可以通過執行指令"ollama run gemma3"來體驗最新的27B模型。

Ollama 的 Gemma3-27B 模型卡
6. DeepSeek:DeepSeek R1 是由中國團隊開發的開源大型語言模型,以其強大的推理能力和低成本優勢受到關注。使用者可以在Ollama或Hugging Face上查找並體驗這一模型,體驗其在數學、編程和邏輯推理等方面的卓越表現。
不過目前DeepSeek 滿血版的尺寸為671B,所以如果要使用的話,必須透過購買起碼16 張H100 才有辦法運行,而Ollama 上面則有提供 DeepSeek-R1 蒸餾後的Llama 與 Qwen 微調模型,尺寸從1.5B 到 70B 都有,如果資源不夠,可以先選擇較小的模型運行

Ollama 的 DeepSeek 的模型卡
以上僅列舉了幾個較為知名的開源語言模型,實際上,隨著人工智能技術的不斷進步,未來將會有更多優秀的模型出現。
如何挑選開源語言模型
在選擇開源語言模型時,我們需要考慮多個因素,包括模型的性能、資源需求以及應用場景。以下是一些常用的評估方法和標準:
1. MMLU(Massive Multi-task Language Understanding):MMLU是一個大規模的多任務語言理解測試,通過一系列選擇題來評估語言模型在各個任務上的表現。目前,DeepSeek-R1 (671B)是開源模型表現最佳的。

MMLU 排行榜
2. ELO評分:ELO是一種常用於錦標賽中對選手進行排名的比較性能指標。在語言模型的語境中,ELO分數反映了人類評估者在多大程度上傾向於選擇某個模型的輸出結果。LMSYS Org推出了一個公開的聊天機器人競技場(Chatbot Arena),根據人類的偏好為各種LLM提供ELO分數。
目前,xAI的閉源大型語言模型Grok-3-Preview-02-24整體表現最佳,而在開源模型中, DeepSeek-R1排名第一,其表現與ChatGPT-4o相當,甚至超過了許多閉源模型。Google DeepMind 的 Gemma-3-27B-it則是開源模型中的第二名。

Chatbot Arena 整體排名
3. 中文能力:在評估語言模型時,大多數評比標準都著重於英文能力。然而,如果我們特別關注模型處理中文的表現,就需要參考專門針對中文設計的評估方法。
中國大陸推出了 CMMLU(中文多任務語言理解評估),旨在全面評測語言模型在中文領域的表現。CMMLU 涵蓋了廣泛的任務,如閱讀理解、問答、摘要生成等,為評估中文語言模型提供了重要參考,而根據 C-MMLU。
而除了CMMLU 外,C-Eval 是一個全面的中文基礎模型評估套件,由 13,948 個選擇題組成,涵蓋 52 個不同學科領域和四個難度等級。這個評估套件旨在透過廣泛的學科覆蓋和不同難度的問題,測試中文基礎模型在各個領域的知識掌握程度和推理能力,全面評估模型的中文理解和生成能力。而目前排行榜第一的是由科大訊飛 摘下王冠。

C-EVAL 排行榜
台灣也開發了自己的中文評估基準,即 TMMLU(台灣多任務語言理解評估)。然而,由於使用者相對較少,其參考價值目前尚不及 CMMLU。
近期,Chatbot Arena 推出了專門的中文模型比拼,為評估中文語言模型提供了新的視角。在這一比拼中,Google DeepMind 的閉源大型語言模型 Gemini-2.0-Flash-Thinking-Exp-01-21 表現最為出色,展現了卓越的中文處理能力。
在開源語言模型方面,DeepSeek-R1 在中文能力上位居第一,成為開源中文語言模型的佼佼者。

Chatbot Arena 中文排名
綜合考慮 CMMLU、TMMLU 以及 Chat Arena 的中文模型比拼結果,我們可以更全面地評估語言模型在中文領域的表現,為選擇合適的中文語言模型提供重要參考。
4. 性價比:除了模型的性能,我們還需要考慮模型的資源需求和性價比。根據提供的表格,Gemma3 的模型在性價比方面表現出色,即以最低的成本獲得了最佳的性能表現,對於GPU資源有限的使用者來說非常友好。

模型性價比排行榜,越左上角 CP 值越高
在選擇開源語言模型時,我們需要綜合考慮模型的性能、資源需求、應用場景以及性價比等多個因素。透過參考MMLU、ELO評分、中文能力和性價比等指標,我們可以選出最符合自身需求的開源語言模型。
不過,隨著AI技術的快速發展,如果目前的模型無法實現某些功能,開發者大可不必太過著急。業界笑言,只需躺平一個月,AI大廠就會推出性能更優、成本更低的新型模型,屆時便能實現所需功能。
因此,我們鼓勵開發者和研究者大膽擁抱當前性能最佳的大型語言模型。雖然目前使用成本偏高,但能為客戶帶來更優質的使用體驗。相信隨著技術進步,未來的使用成本將會迅速下降。
2026年開源大型語言模型最新發展
2026年,開源AI生態系統持續以驚人速度演進,多款重量級模型相繼問世,進一步縮短與閉源商業模型的差距。以下介紹目前最值得關注的幾款新型開源模型,以及企業採用的最新趨勢。
Llama 4:Meta 的原生多模態新世代
Meta 於2025年4月正式發布 Llama 4 系列,標誌著開源模型正式進入原生多模態時代。Llama 4 主要有兩款開放版本:Llama 4 Scout(輕量高效)與 Llama 4 Maverick(170億活躍參數、1280億總參數、MoE架構,上下文窗口長達100萬 token)。訓練資料超過30兆 token,支援200種以上語言。Maverick 在多項基準測試中表現優於 GPT-4o 與 Gemini 1.5 Pro,而尚未公開的 Behemoth 版本(約2兆參數)更被認為可與 GPT-5 一較高下。值得注意的是,Llama 4 授權仍含有部分商業限制(例如歐盟地區條款),因此業界對其「真開源」身份仍有所爭議。
DeepSeek V3.2 與 Qwen3.5:中國開源模型持續領跑
中國方面,DeepSeek 於2025年底推出 DeepSeek V3.2,採用全新的稀疏注意力機制(DSA),大幅降低長文本推理的運算複雜度,在代理(Agent)工作負載上的表現可比肩 GPT-5,且繼續以 MIT 授權開源。阿里巴巴雲的 Qwen3.5 則於2026年2月發布,旗艦版 397B-A17B MoE 模型支援201種語言,並支援「思考模式」與「對話模式」動態切換,特別適合需要複雜推理的企業應用場景。法國 Mistral AI 亦於同期推出 Mistral Large 3(41B 活躍參數、675B 總參數,Apache 2.0 授權),在開源非推理模型排行榜奪得第二名。
企業採用趨勢:混合策略成為主流
根據2026年最新市場調查,企業級 LLM 採用率已從2023年的不足5%躍升至超過80%。已有41%的企業計畫擴大開源模型使用比例,另有37%的企業採取「混合 AI 策略」——同時運用開源與閉源模型,在成本、效能、資料治理與供應商風險之間取得最佳平衡。Llama 4、DeepSeek V3.2、Qwen3.5 等頂尖開源模型在主流基準測試上已與 GPT-4 及 Claude 相當,且差距持續縮小,開源模型即將迎來更大規模的企業部署浪潮。
結論
近年來,開源語言模型如雨後春筍般湧現,為人工智慧領域帶來了革命性的變革。這些開源模型在性能上已經不遑多讓,甚至在某些任務上超越了閉源模型。從Meta的Llama系列到中國的DeepSeek R1,開源AI生態系統正在迅速發展,降低了AI應用的門檻,並為不同需求的使用者提供了多樣化的選擇。
展望未來,除非GPT-5能帶來顛覆性突破,否則模型性能的進一步提升可能面臨邊際效益遞減。DeepSeek R1的崛起展示了降低成本同時保持高性能的可能性,這種趨勢可能會推動整個行業朝著更高效的方向發展。
對新創公司而言,要在這個領域脫穎而出,必須尋找新的突破點,如功能串接協力、針對特定內容進行模型微調,以及探索垂直領域細分、多模態模型和智能代理(Agent)技術等新方向。
根據人工智慧大神吳恩達(Andrew Ng)最近的倡議,智能代理(AI Agent)或許是人工智慧研究的另一片新藍海。它結合了大型語言模型和外部API的優勢,實現了單一模型無法完成的複雜任務。儘管AI Agent的架構設計複雜,但這也為新創公司提供了機遇。
最後,我們鼓勵所有企業都應該開始思考如何擁抱開源,充分利用開源模型的優勢,積極探索AI技術的應用,推動業務創新和發展,將是未來企業保持競爭力的關鍵。
如果您對如何將開源語言模型應用於您的業務有任何想法或疑問,歡迎隨時與大數軟體聯繫,我們很樂意與您分享見解,共同探討開源時代的無限可能。