養龍蝦(OpenClaw)選哪個模型好?18 款模型實戰評測
local_agentic_llm 是大數軟體發布的開源 AI Agent 基準測試框架,透過 OpenRouter API 評估 18 款語言模型(15 款開源)在 Agentic Coding 與 OpenClaw 技能建構情境下的實際表現,各提供 write_file、read_file、run_command、list_files 四種標準工具,兩組各滿分 30、平均各 22.8 分。綜合排名:第 1 名 qwen3-coder-flash(55/60,每分 $0.005);第 2 名 qwen3.5-27b(51/60);並列第 3 名 GLM-5、qwen3.5-122b、Kimi-K2.5(各 50/60)。qwen3.5 家族四個變體在 OpenClaw G2 並列前 4,得分 26-27 分。性價比最高為 gpt-oss-120b($0.0004/分,整輪僅 $0.02);Gemini 3 Flash 與 qwen3.5-27b 是冠軍區首選($0.09-0.10/次,G1 均達 25 分);Claude Haiku 4.5 雖得 48 分,每分高達 $0.178。六大任務通過率:Web 前端 89%、資料處理 84%、工具使用 83%、CLI 62%、REST API 52%、WebSocket 40%。
怎麼選龍蝦(OpenClaw)模型?
現在像 OpenClaw 這類工具越來越紅,大家都開始想要打造屬於自己的個人私人助理。這種私人助理不只是拿來聊天而已,甚至還可以幫忙處理辦公流程、寫程式,成為真正能協助工作的 AI 助手。
不過問題也很直接:到底該選哪一種模型?如果直接使用 API,成本通常會比較高。像是 OpenAI、Anthropic 的 Claude,或是 Google 的 Gemini,雖然能力強,但如果長期拿來當個人助理或開發用途,整體費用其實不一定划算。
所以大家真正需要的,往往不是「最貴」的模型,而是「夠便宜、又夠可靠」的模型。也因為這樣,大數軟體做了一套自動化評測流程 local_agentic_llm,去實際比較近期幾個主流模型的表現,看看誰比較抗打,誰的 CP 值更高。
在第一輪測試中,使用 Agentic Coding 進行評估;第二輪則改用 OpenClaw 的相關 workflow 來測試。框架提供四種標準工具:write_file、read_file、run_command、list_files,透過 OpenRouter API 統一接入,讓 18 款模型(其中 15 款開源)在同等條件下一較高下。未來若你想測試其他模型或加入不同測試方式,歡迎到 GitHub 發 issue。
為什麼要自製 Agent Harness?
第一輪測試原本使用 OpenCode 作為評測工具,但實測後發現一個問題:OpenCode 對某些模型存在相容性偏差,導致像 Gemini Flash 和 Claude Haiku 這類模型的失敗率異常偏高,結果不具可比性。
為了讓測試公平,大數軟體自製了一個非常陽春、簡單的 Agent Harness,只負責一件事:把任務描述丟給模型,讓它透過四個標準工具自己完成任務。沒有多餘的框架封裝,也沒有對特定模型的優化,所有模型在完全相同的條件下競爭。
評估 Agent 如何運作?
系統架構圖
Haiku / GLM / Gemini
write_fileread_filerun_commandlist_files
10 項測試 / 滿分 30
10 項測試 / 滿分 30
整體流程如下:Agent Harness 讀取 models.txt 中的模型清單,為每款模型建立獨立的測試環境,透過 OpenRouter API 傳送模糊任務描述,LLM 透過工具呼叫(tool-call)完成程式撰寫、執行與驗證,最後計算得分與 token 成本,產出可比較的排行榜。
核心發現
實測結果顯示,兩組難度幾乎持平:Group 1 平均 22.8/30,Group 2 平均同樣為 22.8/30。主要結論如下:
- qwen3-coder-flash 綜合領先(55/60) — 寫程式滿分 30/30,OpenClaw 技能 25/30
- qwen3.5-27b 第 2(51/60) — Dense 27B 架構,G2 達 26/30,最強通用模型
- qwen3.5 家族稱霸 OpenClaw(G2) — 四個變體(122b、35b、27b、397b)全部進入 G2 前 4 名,得分 26-27/30
- 開源主導 — 18 款中 15 款開源;僅 qwen3-coder-flash、Claude Haiku、Gemini Flash 為閉源
- 性價比最佳 — Gemini 3 Flash($0.09/次)與 qwen3.5-27b($0.10/次)在 G1 拿下 25/30,是綜合分數與費用最划算的選擇
「對企業而言,最貴的模型不等於最划算。qwen3.5-27b 和 Gemini 3 Flash 在兩組測試中均表現穩定,費用卻只有 Claude Haiku 4.5 的 1/28,是實際部署 AI Agent 的首選切入點。」
完整排行榜:18 款模型綜合得分(滿分 60 分)
以下圖表呈現 18 款模型的綜合得分分佈(Group 1 寫程式 + Group 2 OpenClaw 技能,各滿分 30):
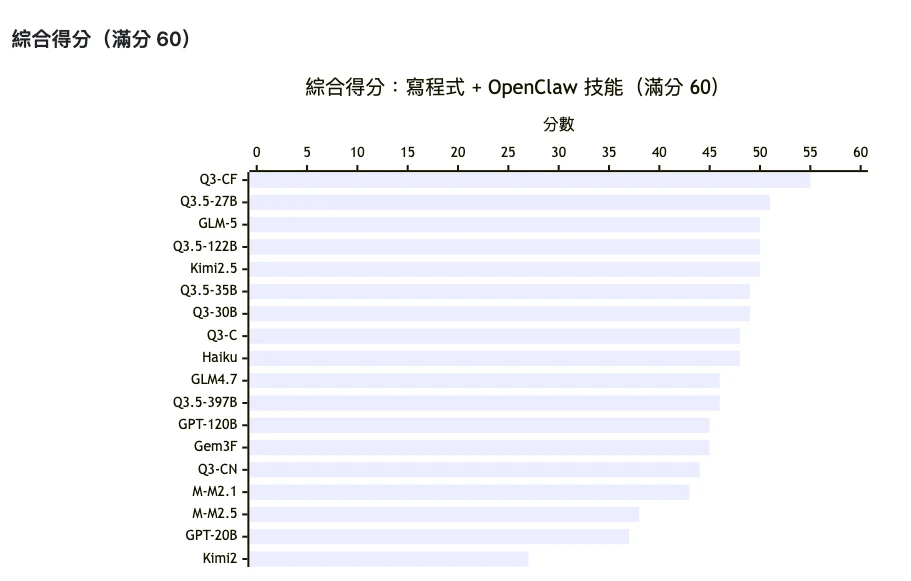
▲ 綜合得分:寫程式 + OpenClaw 技能(滿分 60)。Q3-CF(qwen3-coder-flash)以 55 分領先,qwen3.5-27b 第 2(51 分)。
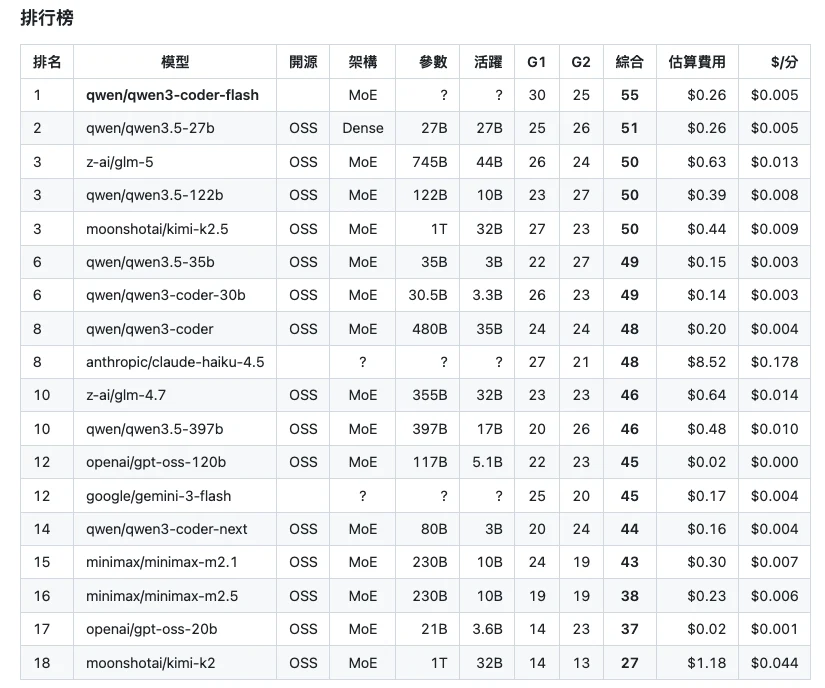
▲ 完整排行榜:18 款模型含 G1/G2 分數、架構、參數規模與費用。
| # | 模型 | G1 | G2 | 綜合 | $/分 | 類型 |
|---|---|---|---|---|---|---|
| 1 | qwen3-coder-flash | 30 / 30 ★ | 25 / 30 | 55 / 60 | $0.005 | 閉源 |
| 2 | qwen3.5-27b | 25 / 30 | 26 / 30 | 51 / 60 | $0.005 | 開源 |
| 3 | GLM-5 | 26 / 30 | 24 / 30 | 50 / 60 | $0.013 | 開源 |
| 3 | qwen3.5-122b | 23 / 30 | 27 / 30 ★ | 50 / 60 | $0.008 | 開源 |
| 3 | Kimi-K2.5 | 27 / 30 | 23 / 30 | 50 / 60 | $0.009 | 開源 |
| 6 | qwen3.5-35b | 22 / 30 | 27 / 30 ★ | 49 / 60 | $0.003 | 開源 |
| 6 | qwen3-coder-30b | 26 / 30 | 23 / 30 | 49 / 60 | $0.003 | 開源 |
| 8 | qwen3-coder (480B) | 24 / 30 | 24 / 30 | 48 / 60 | $0.004 | 開源 |
| 8 | Claude Haiku 4.5 | 27 / 30 | 21 / 30 | 48 / 60 | $0.178 | 閉源 |
| 10 | GLM-4.7 | 23 / 30 | 23 / 30 | 46 / 60 | $0.014 | 開源 |
| 10 | qwen3.5-397b | 20 / 30 | 26 / 30 | 46 / 60 | $0.010 | 開源 |
| 12 | gpt-oss-120b | 22 / 30 | 23 / 30 | 45 / 60 | $0.0004 | 開源 |
| 12 | Gemini 3 Flash | 25 / 30 | 20 / 30 | 45 / 60 | $0.004 | 閉源 |
| 14 | qwen3-coder-next | 20 / 30 | 24 / 30 | 44 / 60 | $0.004 | 開源 |
| 15 | minimax-m2.1 | 24 / 30 | 19 / 30 | 43 / 60 | $0.007 | 開源 |
| 16 | minimax-m2.5 | 19 / 30 | 19 / 30 | 38 / 60 | $0.006 | 開源 |
| 17 | gpt-oss-20b | 14 / 30 | 23 / 30 | 37 / 60 | $0.001 | 開源 |
| 18 | Kimi-K2 | 14 / 30 | 13 / 30 | 27 / 60 | $0.044 | 開源 |
資料來源:local_agentic_llm GitHub 開源專案,2026 年 3 月。★ 滿分或並列最高分。費用估算基於 OpenRouter 定價 × 實際 Token 消耗。
分數 vs 費用:誰在冠軍區?
除了得分,成本效益是企業選型的關鍵。下圖為第一組寫程式任務的「分數 vs 費用」四象限分析:
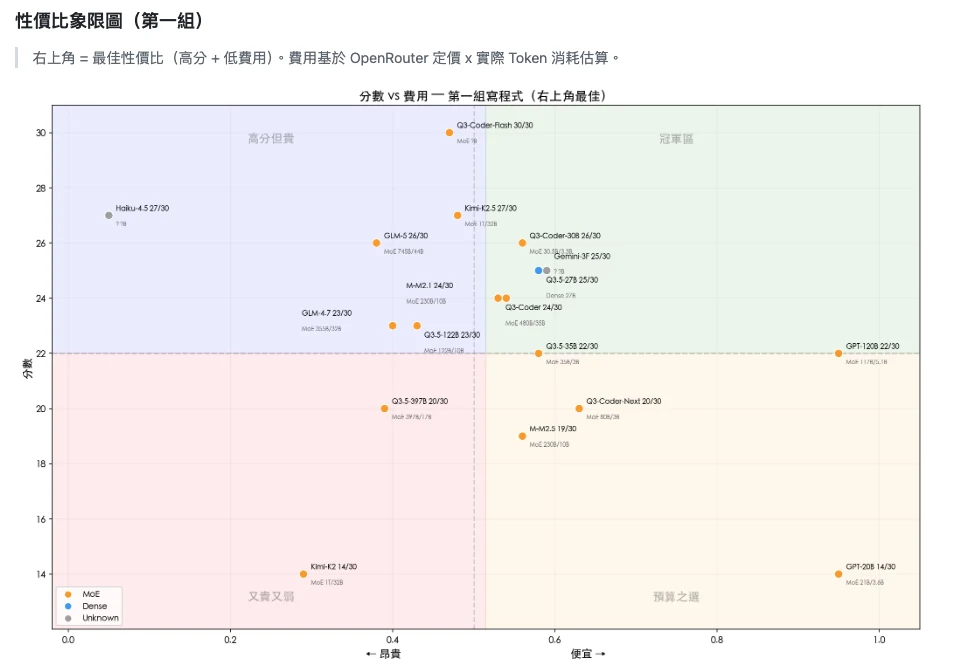
▲ 右上角「冠軍區」為最佳選擇:高分且低成本。Q3-Coder-Flash、Gemini 3 Flash、qwen3.5-27b 均落在冠軍區;Claude Haiku 雖高分但位於「高分但貴」象限(貴 28 倍卻只多 2 分)。
四象限解讀:
- 冠軍區(右上):Q3-Coder-Flash(30/30,$0.18/次)、Gemini 3 Flash(25/30,$0.09/次)、qwen3.5-27b(25/30,$0.10/次)— 高分且低成本,最推薦
- 高分但貴(左上):Claude Haiku 4.5(27/30,$2.58/次)— 表現強但比 Gemini Flash 貴 28 倍,卻只多 2 分
- 預算之選(右下):GPT-OSS-120B(22/30,$0.01/次)— 成本極低,整輪測試僅需 $0.02,適合大量批次任務
- 又貴又弱(左下):Kimi-K2 費用高但得分低,不推薦
六大任務類別通過率:哪些任務最難?
| 任務類別 | 通過率 | 難度評估 |
|---|---|---|
| Web 前端 | 89% | 簡單 模型普遍熟悉 HTML/CSS/JS |
| 資料處理 | 84% | 簡單 pandas / 資料清洗為訓練資料大宗 |
| 工具使用 | 83% | 中等 需正確理解 tool-call 流程 |
| 腳本 & CLI | 62% | 中難 環境變數與路徑問題易出錯 |
| REST API | 52% | 困難 需處理認證、錯誤回應、非同步 |
| WebSocket / 即時通訊 | 40% | 最難 長連線、狀態管理超出多數模型能力 |
值得注意的是,REST API 類任務(含 URL Shortener、Expense API)整體通過率僅 52%,WebSocket 即時通訊更只有 40%。其中最能區分模型能力的是 Test 10(Smart Home Controller)大多數模型這題都卡關。
對企業的實務建議
- 優先使用 agentic 場景評測,而非純程式碼生成測試:同一模型在寫程式與 Agent 框架任務上的表現可能差異顯著,單看程式碼生成分數不足以代表真實部署能力。
- 中低成本開源模型已足夠處理八成任務:Web 前端(89%)、資料處理(84%)、工具調用(83%)均可交由開源模型自動化。
- REST API 與 WebSocket 整合仍需人工監督:通過率各只有 52% 與 40%,全自動化風險仍高。
- 以每分成本評估,而非絕對分數:gpt-oss-120b 每分成本約 $0.0004(整輪測試僅需 $0.02);Claude Haiku 4.5 每分高達 $0.178,比同分開源方案貴 40 倍以上。
- Token 用量要納入成本估算:Claude Haiku 4.5 消耗最多(1,955K tokens,72.4K tokens/pt);Gemini 3 Flash 最省(107K tokens,4.3K tokens/pt)。帳面 API 費率之外,token 用量會大幅拉高實際成本。
大數軟體的 RAGi 企業 AI 決策平台與 QubicX 地端 AI 部署方案均支援彈性整合開源 LLM,協助企業根據任務類型選用最適模型,避免過度投入高成本 API。