MLX 推論框架基準測試:Apple Silicon M5 Max 跑 35B LLM 實測比較
原始基準測試資料來源:
github.com/ywchiu/mlx_benchmark_lab
完整 JSONL 結果、繪圖腳本與雙語報告皆於此 Repository 開源公開。
MLX 是 Apple 為自家 Silicon 晶片設計的機器學習框架,能在 Mac 上以統一記憶體(Unified Memory)直接執行大型語言模型(LLM)推論,無需 NVIDIA GPU。隨著 rapid-mlx、omlx、dflash-mlx、mlx-vlm 四大推論引擎陸續推出,企業在地端 AI(On-Premise AI)部署上多了 Apple Silicon 這個極具吸引力的選項。本文以 ywchiu/mlx_benchmark_lab 公開基準測試(Apple M5 Max、64 GB 統一記憶體、35B 參數 MoE 量化模型)為依據,深入解析四大框架在不同上下文長度下的效能與穩定度,並提供企業地端 AI 選型建議。
什麼是 MLX?Apple Silicon 上的 LLM 推論框架
MLX 是 Apple 機器學習研究團隊在 2023 年底開源的數值運算框架,其核心特色是針對 Apple Silicon(M1/M2/M3/M4/M5 系列晶片)的統一記憶體架構深度優化。與必須在 CPU 與 GPU 之間搬移張量資料的傳統 CUDA 流程不同,MLX 的張量可在 CPU、GPU、Neural Engine 之間零拷貝(Zero-Copy)共享,大幅降低記憶體頻寬瓶頸。這項架構優勢讓配備 64 GB 以上統一記憶體的 Mac Studio 與 MacBook Pro,成為地端執行 30B–70B 參數 LLM 的可行平台。
在 MLX 之上,社群陸續發展出多款專注於 LLM 推論的引擎,每款皆針對不同的應用場景做了取捨。本次基準測試涵蓋的四款主流框架包括:rapid-mlx(功能彈性、支援分頁 KV Cache 與多 Token 預測)、omlx(長文脈穩定度與整體效能均衡)、dflash-mlx(採用推測式解碼 Speculative Decoding,短文脈速度最快)、以及 mlx-vlm(唯一支援圖像、影片、語音多模態輸入的框架)。
基準測試方法與硬體環境
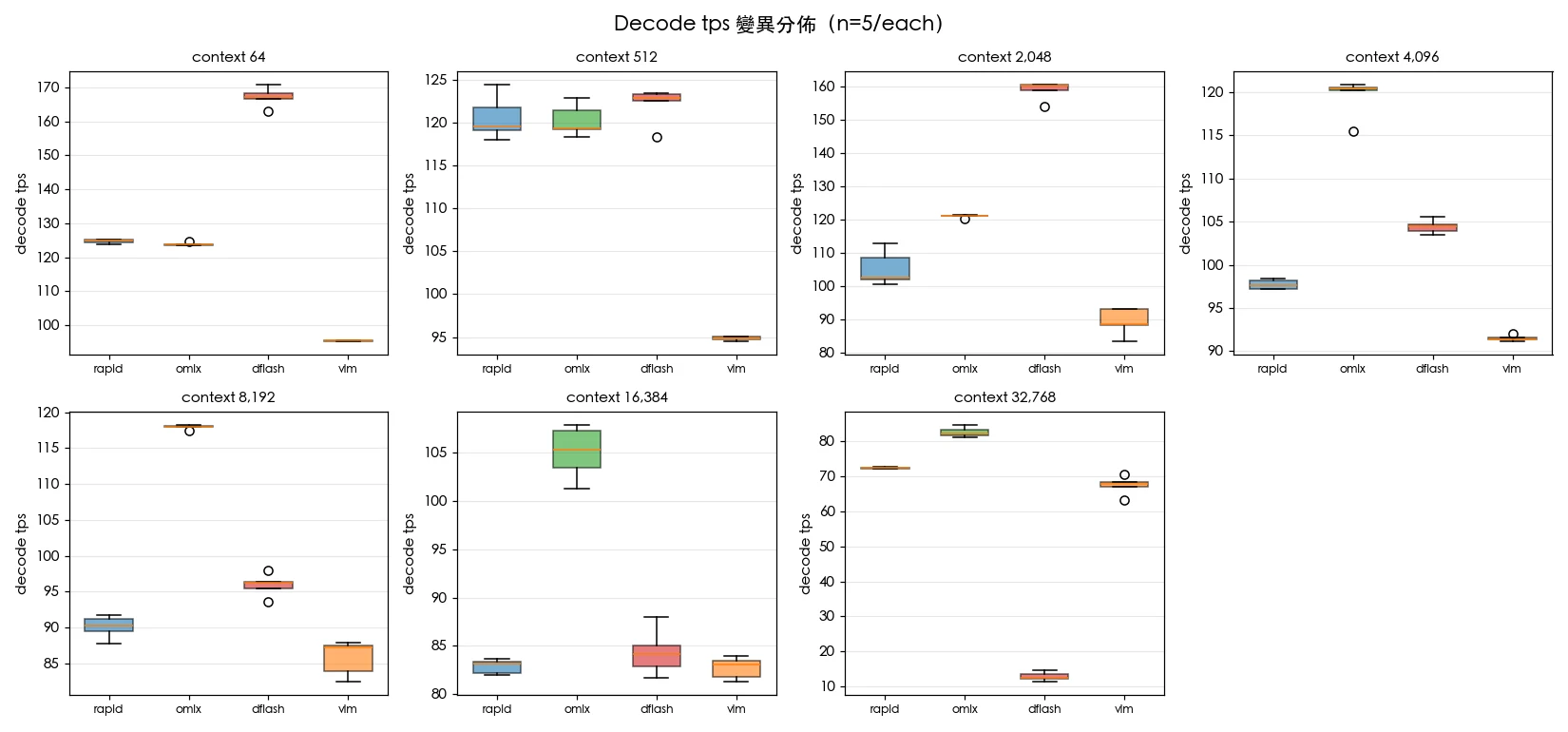
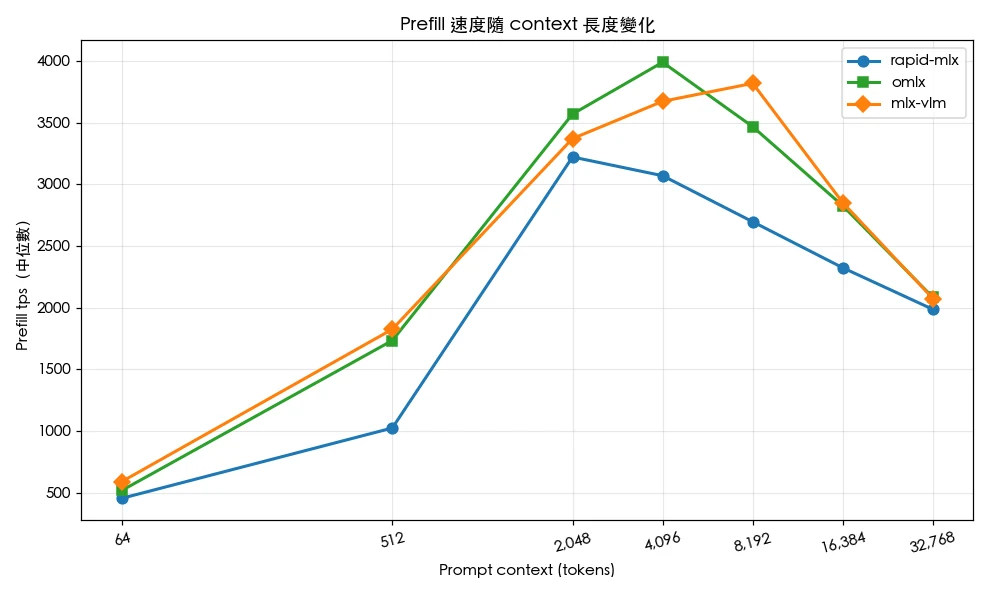
本次測試使用 Apple M5 Max 晶片搭配 64 GB 統一記憶體,模型為 mlx-community/Qwen3.6-35B-A3B-4bit——這是 35B 總參數、3B 啟動參數的 4-bit 量化混合專家(MoE)模型。為確保結果可比較,所有框架都透過 OpenAI 相容 API 啟動本地伺服器,並明確關閉 Prefix Cache(前綴快取),以量測真實的冷啟動 Prefill 效能。每個上下文長度執行 5 次重複測試,計算中位數、平均數、標準差。測試的上下文長度涵蓋 7 個區間:64、512、2,048、4,096、8,192、16,384、32,768 tokens。
測試結果:解碼速度與長文脈表現
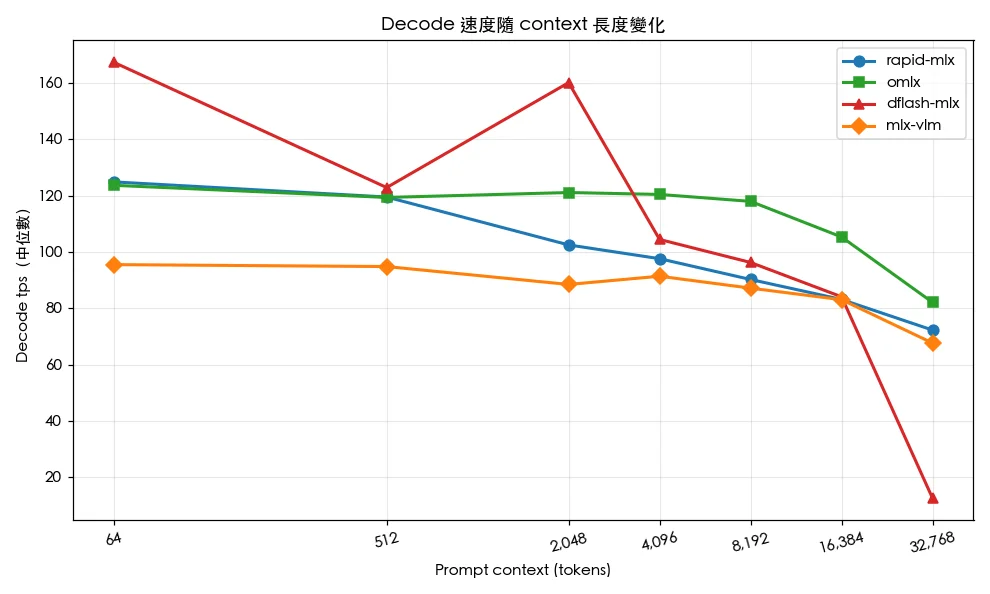
| 上下文長度 | rapid-mlx | omlx | dflash-mlx | mlx-vlm |
|---|---|---|---|---|
| 64 tokens | 124.9 | 123.7 | 167.3 | 95.5 |
| 512 tokens | 119.5 | 119.4 | 122.9 | 94.8 |
| 2,048 tokens | 102.5 | 121.1 | 160.1 | 88.5 |
| 4,096 tokens | 97.6 | 120.4 | 104.5 | 91.4 |
| 8,192 tokens | 90.3 | 118.0 | 96.3 | 87.2 |
| 16,384 tokens | 83.2 | 105.3 | 84.1 | 83.1 |
| 32,768 tokens | 72.3 | 82.1 | 12.6 ⚠️ | 67.7 |
單位:tokens/sec(中位數),數字越高越好。資料來源:ywchiu/mlx_benchmark_lab,2026-05-09。
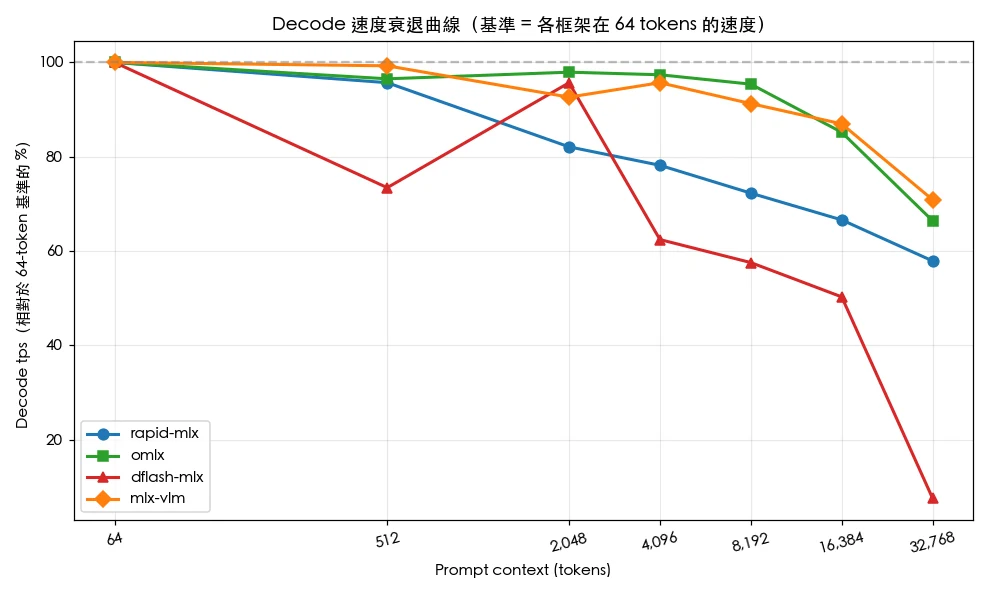
關鍵觀察一:dflash-mlx 在短文脈(≤ 2K)展現約 35% 的解碼速度優勢,這歸功於推測式解碼技術;但在 32K 長文脈下發生災難性衰退至 12.6 tps,比其他框架慢約 6 倍,顯示其架構難以擴展至長上下文。
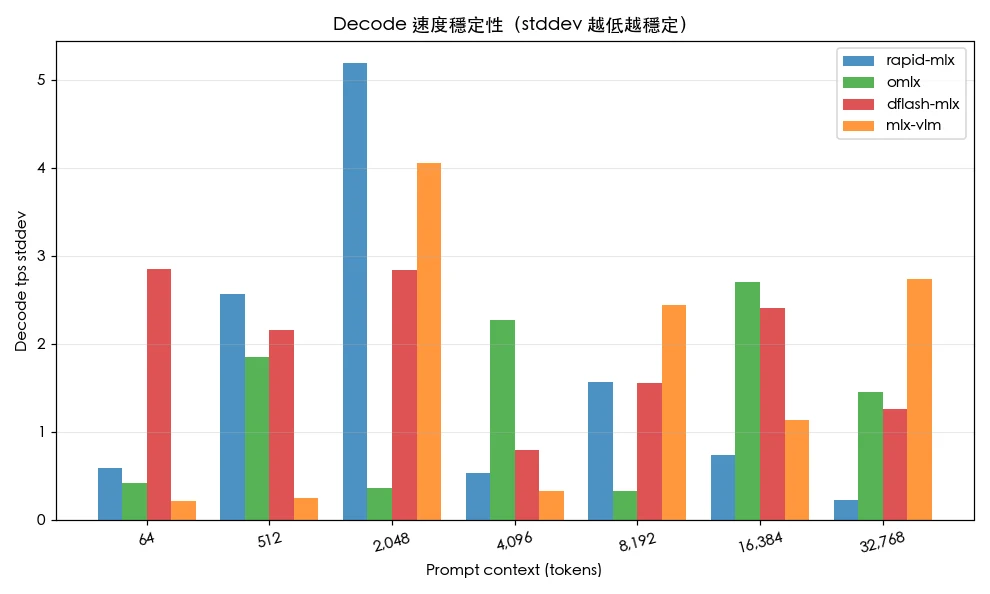
關鍵觀察二:omlx 是長文脈場景的全能冠軍,從 4K tokens 開始全面領先,在 16K 仍能維持 100 tps 以上,32K 達 82.1 tps,且標準差最小,是穩定度最高的框架。
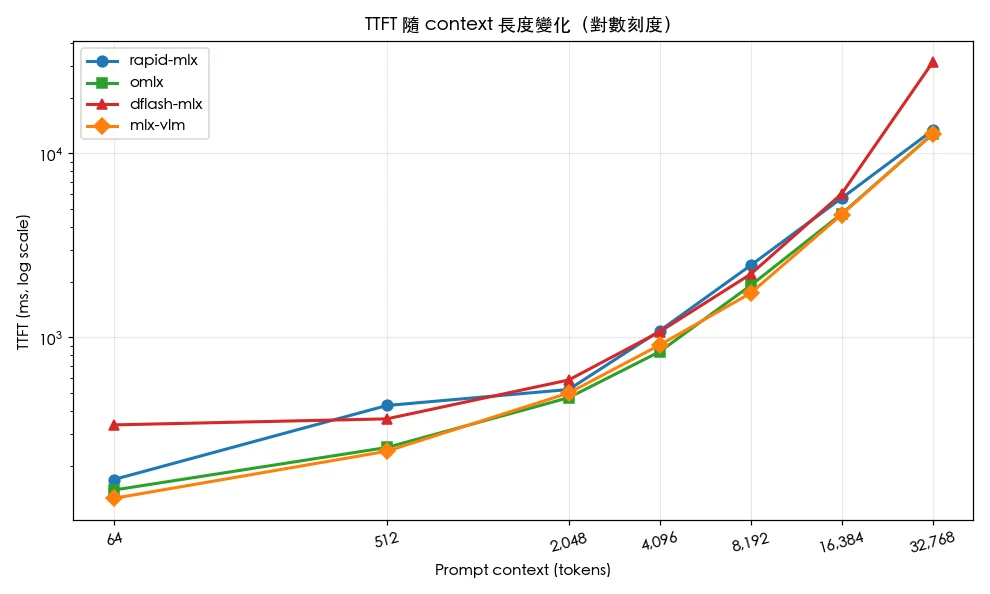
關鍵觀察三:所有框架在從 64 到 32,768 tokens 的擴展過程中皆出現顯著衰退,但衰退程度從 omlx 的 34% 到 dflash-mlx 的 92% 相差極大。TTFT(首 Token 延遲)方面差異更大,跨越近三個數量級——dflash-mlx 在 32K 上下文下飆升至 31 秒,超過其他框架的兩倍。
如何選擇適合應用場景的 MLX 框架
omlx — 長文脈與企業生產系統首選:從 4K tokens 起全面領先,且具備四大框架中最低的標準差,是企業 RAG、文件摘要、長篇法律或財報分析的最佳選擇。穩定度高代表 SLA 容易達標,可預測的延遲表現也讓容量規劃更為直觀。
dflash-mlx — 短文脈高吞吐專用:在 64-token 上下文達到 167.3 tps 的爆發力,適合輸入長度可預測且明確控制在 2K tokens 以下的應用,例如結構化資料分類、SQL 生成、簡短客服回覆。但須嚴格避免長上下文場景。
rapid-mlx — 功能彈性的中間選擇:在任何上下文長度都不是最快,但表現相對穩定,且具備分頁 KV Cache、Prefix Cache、多 Token 預測等彈性功能。適合需要這些進階特性的研發團隊。
mlx-vlm — 多模態輸入唯一選項:純文字工作負載慢約 25–30%,但是四大框架中唯一支援圖像、影片、語音輸入的框架。如果應用需要 OCR 後影像理解、視訊摘要、或多模態客服機器人,是當前唯一選擇。
對企業地端 AI 部署的啟示
企業地端 AI 部署的關鍵啟示是:硬體與軟體必須整體評估,不能只看 GPU 規格表面上的 TFLOPS 數字。Apple Silicon 在統一記憶體架構下,搭配正確的 MLX 框架,能以更低的硬體成本(單台 Mac Studio 約 USD 4,000)跑得動 35B 參數的量化模型,並達到 80–120 tokens/sec 的解碼速度——這對許多企業內部的 RAG 或智慧客服場景已經足夠。
相較於 NVIDIA H100 動輒 USD 30,000 以上的單卡成本,Apple Silicon 為中小企業與分散式部署提供了極具吸引力的另一條路徑。但企業若要將 Apple Silicon 納入正式生產環境,必須建立框架選型、版本管理、健康檢查、效能監控的完整 MLOps 流程。
LargitData 的 QubicX 地端 AI 平台支援多種硬體後端(NVIDIA GPU、AMD GPU、Apple Silicon),並內建框架抽象層,能依據用戶提交的上下文長度自動選擇最適合的推論引擎,避免企業 IT 團隊需要自行判斷與切換。對於追求資料主權、低延遲、可預測成本的台灣企業,這類自動化的地端 AI 編排能力,是從基準測試走向生產部署的關鍵橋樑。
完整原始 JSONL 結果、繪圖腳本(plot_results.py)、雙語報告皆已開源公開,歡迎在自家 Mac 上重現驗證: github.com/ywchiu/mlx_benchmark_lab