MLX Inference Benchmark: 4 Frameworks on Apple M5 Max with 35B LLM
Benchmark data source:
github.com/ywchiu/mlx_benchmark_lab
Full JSONL results, plotting scripts, and bilingual reports are all open-sourced in this repository.
MLX is Apple's machine learning framework purpose-built for its Silicon chips, enabling Mac systems to run large language model (LLM) inference directly through Unified Memory without requiring NVIDIA GPUs. With four inference engines now available — rapid-mlx, omlx, dflash-mlx, and mlx-vlm — Apple Silicon has become an attractive option for enterprise on-premise AI deployment. Based on the public ywchiu/mlx_benchmark_lab benchmark (Apple M5 Max, 64 GB unified memory, 35B-parameter quantized MoE model), this article analyzes the performance and stability of all four frameworks across context lengths and provides enterprise on-premise AI selection guidance.
What Is MLX? The LLM Inference Framework Built for Apple Silicon
MLX is an open-source numerical computing framework released by Apple's machine learning research team in late 2023, deeply optimized for the unified memory architecture of Apple Silicon (M1/M2/M3/M4/M5 series). Unlike traditional CUDA workflows that must move tensor data between CPU and GPU, MLX tensors can be shared zero-copy across CPU, GPU, and Neural Engine, dramatically reducing memory bandwidth bottlenecks. This architectural advantage makes Mac Studio and MacBook Pro with 64 GB or more of unified memory viable platforms for running 30B–70B parameter LLMs on-premise.
On top of MLX, the community has developed multiple inference engines specialized for LLMs, each making different trade-offs. The four mainstream frameworks covered in this benchmark are: rapid-mlx (flexible features with paged KV cache and multi-token prediction), omlx (balanced long-context stability and overall performance), dflash-mlx (fastest at short context using speculative decoding), and mlx-vlm (the only framework supporting image, video, and audio multimodal input).
Benchmark Methodology and Hardware Setup
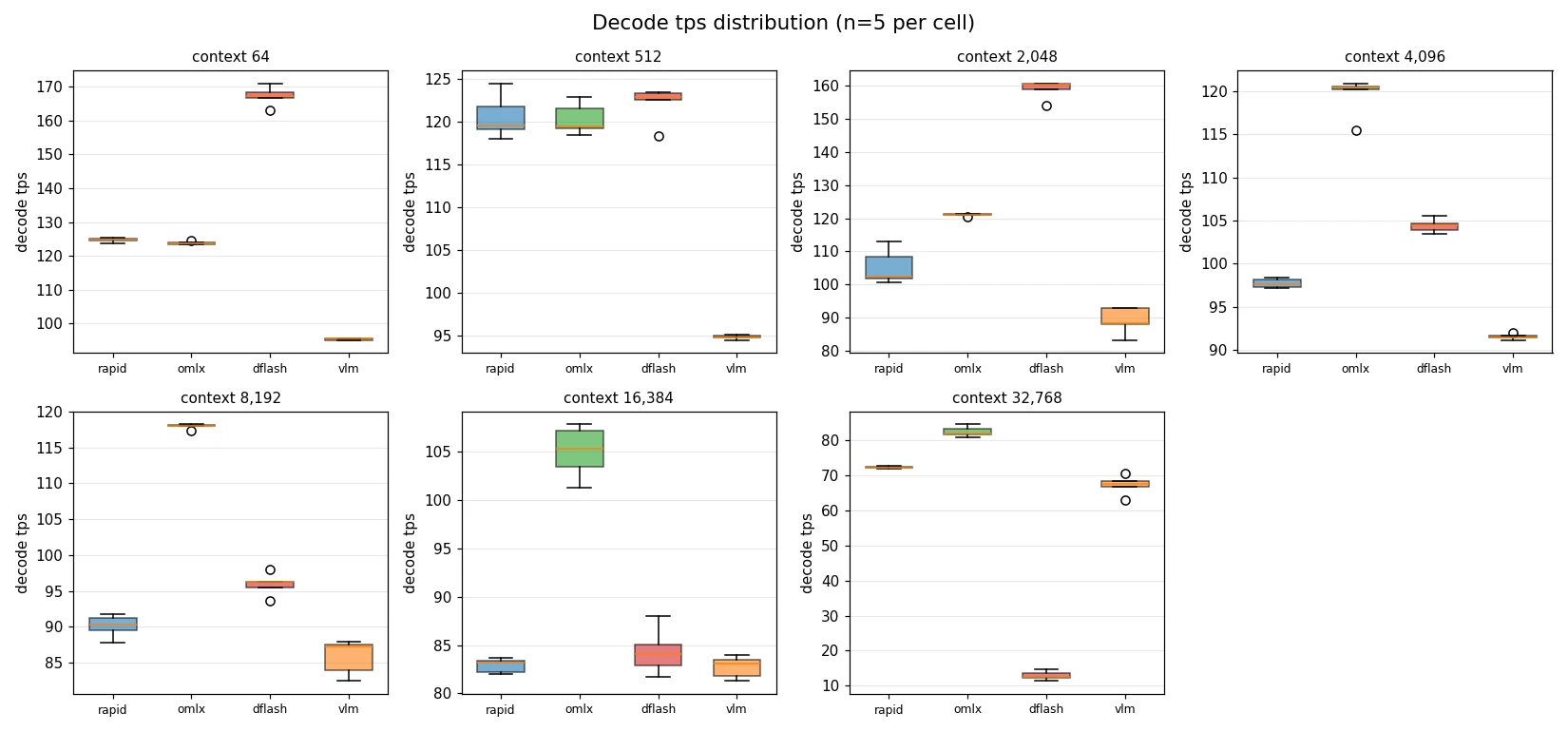
Testing uses an Apple M5 Max with 64 GB unified memory, with the model being mlx-community/Qwen3.6-35B-A3B-4bit — a 4-bit quantized mixture-of-experts (MoE) model with 35B total parameters and 3B active parameters. To ensure comparable results, all frameworks are launched as local servers via OpenAI-compatible APIs, with prefix caching explicitly disabled to measure genuine cold-start prefill performance. Each context length is tested with five repeated runs, with median, mean, and standard deviation calculated. Context lengths span seven intervals: 64, 512, 2,048, 4,096, 8,192, 16,384, and 32,768 tokens.
Benchmark Results: Decode Speed and Long-Context Performance
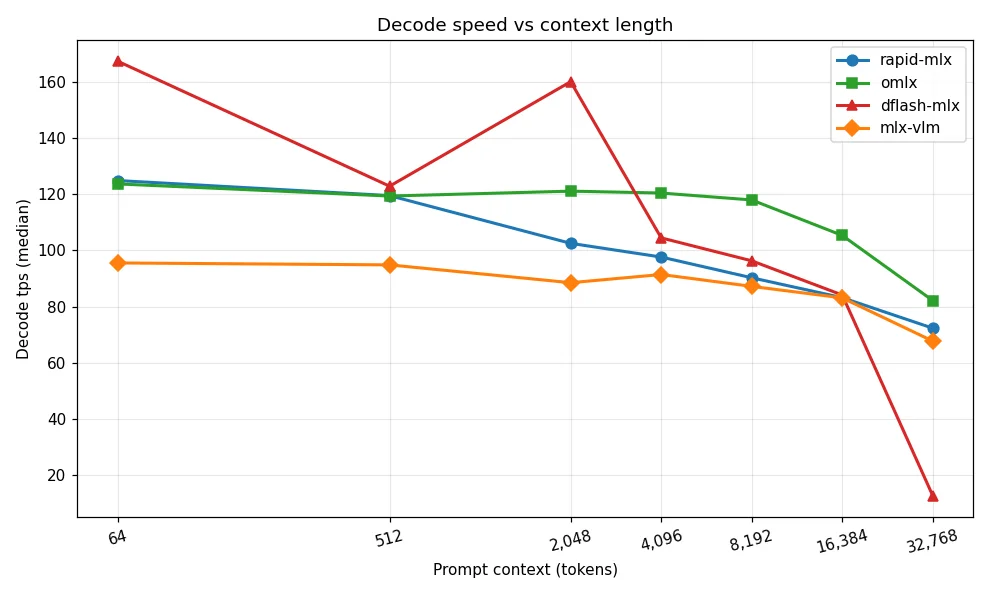
| Context Length | rapid-mlx | omlx | dflash-mlx | mlx-vlm |
|---|---|---|---|---|
| 64 tokens | 124.9 | 123.7 | 167.3 | 95.5 |
| 512 tokens | 119.5 | 119.4 | 122.9 | 94.8 |
| 2,048 tokens | 102.5 | 121.1 | 160.1 | 88.5 |
| 4,096 tokens | 97.6 | 120.4 | 104.5 | 91.4 |
| 8,192 tokens | 90.3 | 118.0 | 96.3 | 87.2 |
| 16,384 tokens | 83.2 | 105.3 | 84.1 | 83.1 |
| 32,768 tokens | 72.3 | 82.1 | 12.6 ⚠️ | 67.7 |
Unit: tokens/sec (median); higher is better. Source: ywchiu/mlx_benchmark_lab, 2026-05-09.
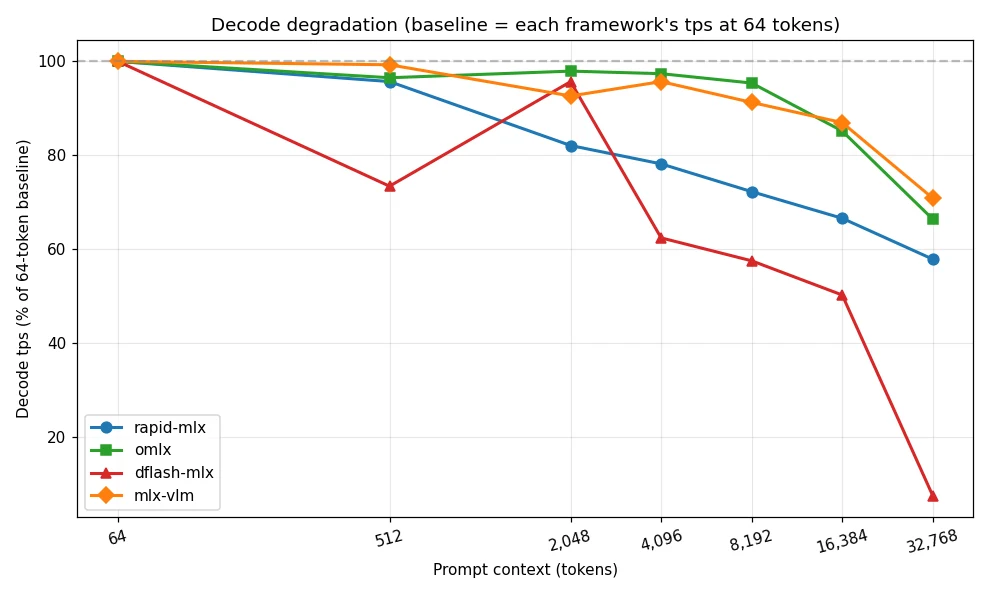
Observation 1: dflash-mlx delivers roughly a 35% decode-speed advantage at short context (≤ 2K) thanks to speculative decoding, but suffers catastrophic degradation to 12.6 tps at 32K — roughly six times slower than the others — revealing its architecture does not scale to long context.
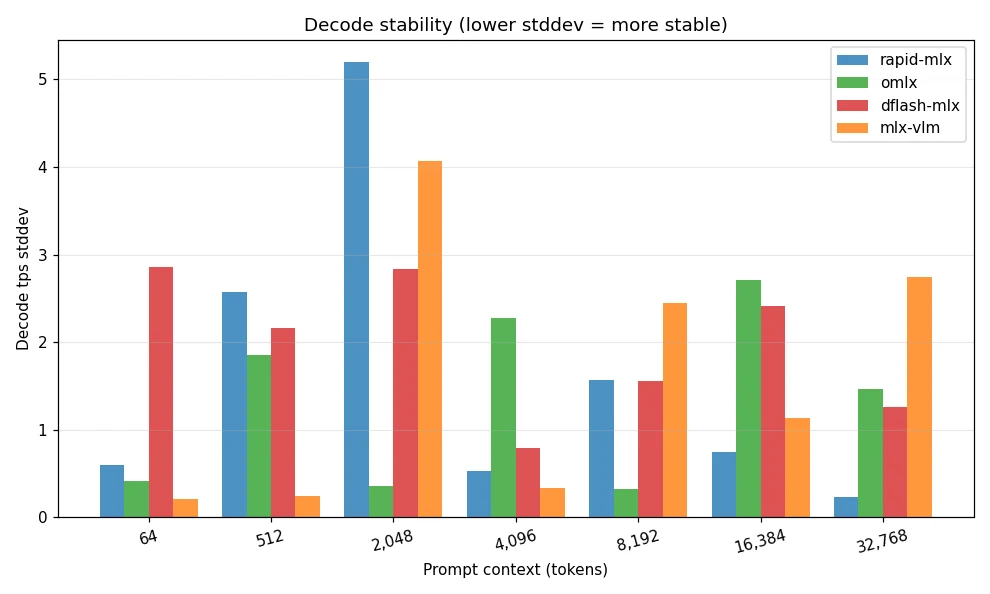
Observation 2: omlx is the all-around long-context champion: it leads from 4K tokens onward, sustains over 100 tps at 16K, reaches 82.1 tps at 32K, and exhibits the lowest standard deviation — making it the most stable framework.
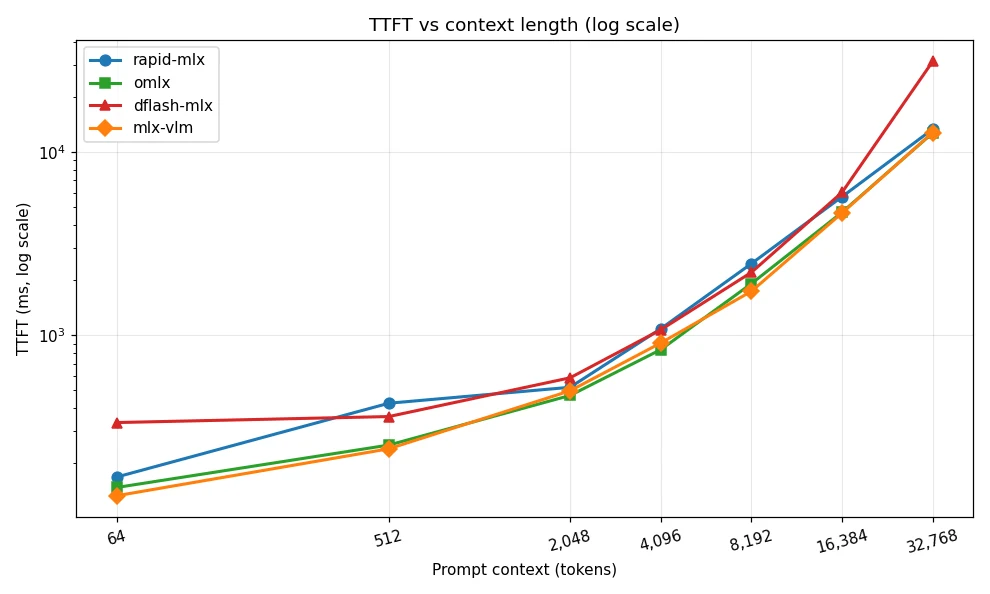
Observation 3: Every framework degrades when scaling from 64 to 32,768 tokens, but the magnitude varies enormously — from 34% for omlx to 92% for dflash-mlx. TTFT shows even greater divergence, spanning nearly three orders of magnitude — dflash-mlx spikes to 31 seconds at 32K context, more than double the next worst.
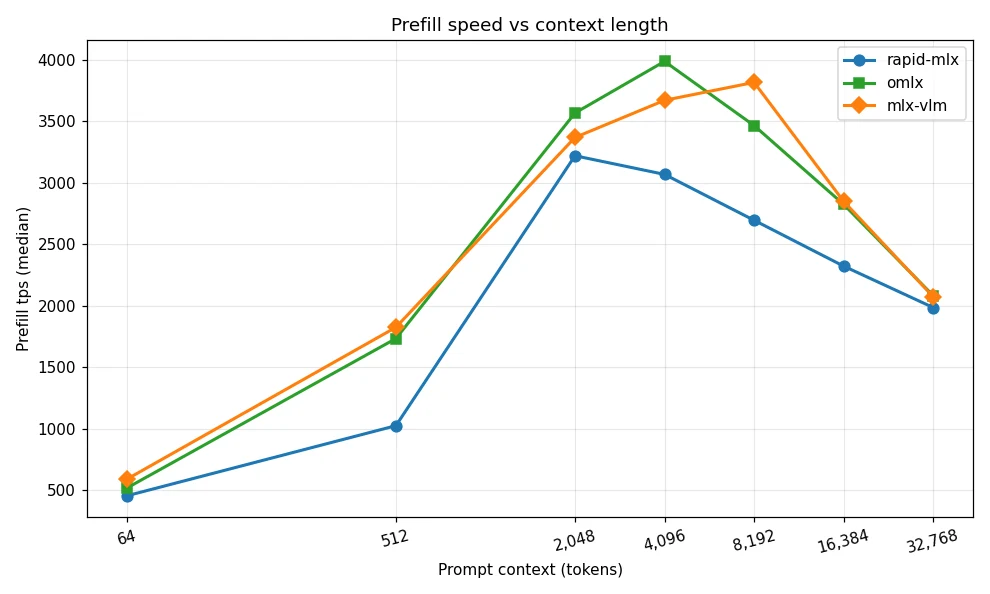
How to Choose the Right MLX Framework
omlx — Top choice for long context and enterprise production: leads across the board from 4K tokens onward with the lowest standard deviation, making it best for enterprise RAG, document summarization, and long-form legal or financial analysis. High stability translates directly to easier SLA attainment.
dflash-mlx — Specialized for short-context high throughput: hits 167.3 tps at 64-token context, ideal for applications where input length is predictable and tightly bounded under 2K tokens — structured data classification, SQL generation, short customer-service replies. Long-context use must be strictly avoided.
rapid-mlx — Flexible middle-ground option: never the fastest at any context length but stays consistently competitive while offering paged KV cache, prefix cache, and multi-token prediction. Suits R&D teams exploring experimental techniques.
mlx-vlm — The only multimodal option: roughly 25–30% slower on pure-text workloads, but the only one of the four supporting image, video, and audio input. For post-OCR image understanding, video summarization, or multimodal customer-service bots, it is currently the only choice.
Implications for Enterprise On-Premise AI Deployment
The key insight for enterprise on-premise AI is that hardware and software must be evaluated together — surface-level GPU TFLOPS numbers are insufficient. With unified memory and the right MLX framework, Apple Silicon can run a 35B-parameter quantized model at 80–120 tokens/sec on hardware costing as little as USD 4,000 per Mac Studio — more than sufficient for many internal enterprise RAG or smart customer-service use cases.
Compared to a single NVIDIA H100 starting above USD 30,000, Apple Silicon offers an extremely attractive alternative path for SMBs and distributed deployments. To bring Apple Silicon into formal production, however, enterprises must establish a complete MLOps process covering framework selection, version management, health checks, and performance monitoring.
LargitData's QubicX on-premise AI platform supports multiple hardware backends (NVIDIA GPU, AMD GPU, and Apple Silicon) with a built-in framework abstraction layer that automatically selects the most suitable inference engine based on submitted context length — eliminating the need for enterprise IT to make and switch this judgment manually. For Taiwanese enterprises that demand data sovereignty, low latency, and predictable costs, this kind of automated on-premise AI orchestration is the crucial bridge between benchmarks and production deployment.
Full raw JSONL results, plotting script (plot_results.py), and bilingual reports are open-sourced — reproduce on your own Mac: github.com/ywchiu/mlx_benchmark_lab