rapid-mlx vs oMLX: MLX Inference Benchmark on Apple M5 Max (35B LLM)
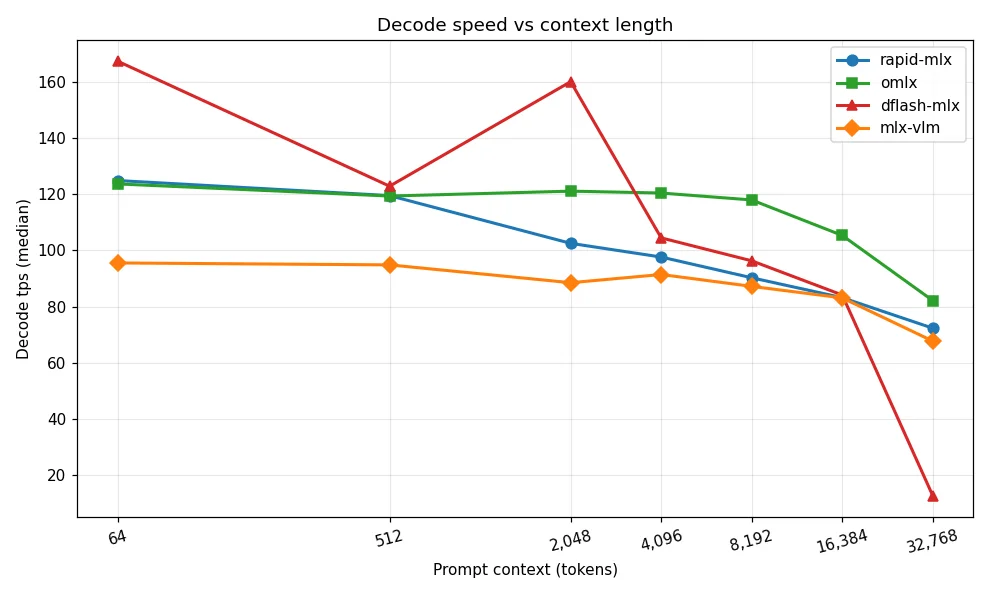
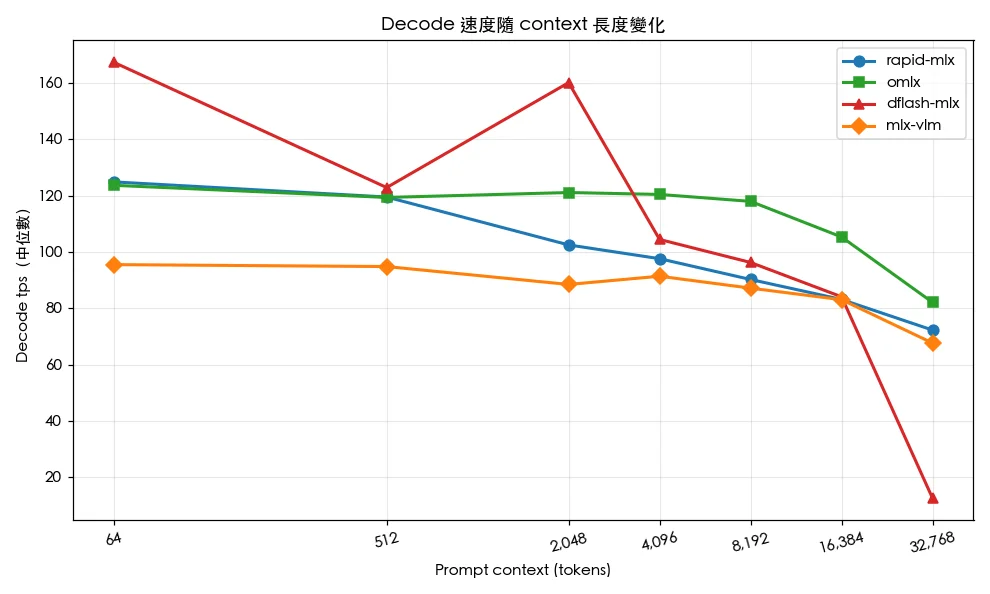
Head-to-head MLX inference benchmark on Apple M5 Max (64 GB unified memory): rapid-mlx vs omlx vs dflash-mlx vs mlx-vlm running a 35B LLM — tokens/sec, time-to-first-token, memory use, and which framework to pick in 2026.
閱讀更多